Domača pamet
Letos smo dobili prve resne jezikovne modele, ki so bili ustvarjeni v slovenščini, s slovenskimi besedili za slovenske uporabnike. Njihove provenience so zelo različne, nameni uporabe tudi, sporočilo pa je obče. Takšne modele potrebujemo, njihova priprava pa zahteva nekaj znanja, računske moči in predvsem dovolj slovenskih besedil. Vse to pri nas imamo, o čemer smo se pogovorili tudi z avtorjem enega izmed slovenskih modelov.
Veliki jezikovni modeli, ki so jih pripravili tuji giganti in so danes na voljo, so se slovenščine naučili spotoma. Med zbiranjem in prebiranjem vseh mogočih vsebin z interneta so naleteli tudi na slovenska besedila, zato danes ChatGPT, Gemini in LLaMa zmorejo odgovarjati v slovenščini. Poznajo tudi za naš del sveta relevantne dogodke, denimo podrobnosti o slovenski osamosvojitvi, značilnosti Cerkniškega jezera in navezanost slovenskega gospodarstva na Nemčijo. Pa vendarle ti modeli ne dosegajo potenciala, ki je dosegljiv z osredotočenjem na slovenski jezik, torej učenjem na slovenskih vsebinah in ustreznimi usmeritvami.
Znanje o ustvarjanju velikih jezikovnih modelov je danes na internetu dostopno vsakomur, LLaMa pa je dostopna v celoti in jo lahko vsakdo tudi prilagodi. Ovire za razvoj lastnih jezikovnih modelov padajo tudi zaradi čedalje nižje cene računske moči, ki je potrebna za njihovo urjenje, zato ni presenetljivo, da so začeli nastajati prvi izdelki izpod domačih rok.
GaMS
V okviru projekta PoVeJMo, ki ga koordinirajo v Centru za jezikovne vire in tehnologije na Univerzi v Ljubljani, razvijajo več jezikovnih modelov ¬družine GaMS. Septembra so predstavili štiri modele, med katerimi sta dva osnovna, dva pa omogočata uporabo v obliki kleptalnega sogovornika. Gre za modela, ki se trenutno imenujeta GaMS-1B in OPT-GaMS-1B, ter klepetalni različici GaMS-1B-Chat in OPT-GaMS-1B-Chat. Na voljo so na strani Hugging Face na profilu CJVT (https://huggingface.co/cjvt). Vsi so zgrajeni na Facebookovem modelu OPT in imajo milijardo parametrov, s čimer sodijo med manjše modele, ki so prilagojeni za slovenščino. OPT-GaMS-1B uporablja originalni način tokenizacije OPT, kot ga je razvil Facebook, GaMS-1B pa način BPE z velikostjo slovarja 80.000, ki je bil razvit posebej za slovenščino, angleščino in hrvaščino.
Ob tem razvijalci poudarjajo, da je model majhen in ni bil varnostno preverjen ter modificiran, zato ne priporočajo splošne uporabe, torej kot univerzalnega modela (general-purpose). GaMS-1B je bil izurjen na 28 milijardah vhodnih koščkov besedila (tokens), OPT-GaMS-1B pa na 47 milijardah, kar je pri prvem trajalo 60 ur, pri drugem pa 16. Različici Chat sta prilagojeni za pogovore, navadni pa zgolj za enkratne pozive.
Center za jezikovne vire in tehnologije objavlja svoje modele na Hugging Faceu.
SlovenianGPT (in yugoGPT)
A PoVeJMo niso bili prvi, ki so razvili slovenski jezikovni model. Med trenutno dostopnimi tremi družinami so bili v resnici zadnji. Prvi je bil Aleka Gordić, ki je svoj SlovenianGPT s sedmimi milijoni parametrov predstavil že marca letos. Gordić, ki je svojčas delal za Microsoft (projekt HoloLens), kasneje pa poldrugo leto za DeepMind, je osnovno različico modela, ki ni usposobljena za klepet, objavil na Hugging Faceu (https://huggingface.co/gordicaleksa/SlovenianGPT) pod licenco Apache 2.0. Na testu ga je primerjal z Mistralom 7B, LLaMo 2 7B in Gemmo, ki jih je vse premagal.
SlovenianGPT temelji na Mistralu 7B, a je naučen na več deset milijardah koščkov slovenskih besedil (token). Poudaril je, da ima tudi zmogljivejše inačice, ki pa niso javno dostopne. Model je uril na čipih Nvidia H100 poln teden dni, že pred tem pa je na podoben način ustvaril tudi model za srbski jezik. SlovenianGPT je osnovni model, ki ni preverjen, nima varnostnih mehanizmov in ni namenjen izvajanju ukazov po navodilih, temveč deluje kot zelo zmogljivo orodje za dokončevanje oziroma nadaljevanja pozivov z besedilom.
PoVeJMo že objavil kodo in testno zbirko
Le nekaj dni po izidu prejšnje številke Monitorja, 29. septembra, so na CJVT v okviru projekta PoVeJMo objavili tudi svojo kodo in testno zbirko za preizkus modela. Najdemo ju lahko na Githubu (github.com/SloLama/slovenian-llm-eval) in Hugging Faceu (huggingface.co/datasets/cjvt/slovenian-llm-eval). Zbirka podatkov je nadgradnja Gordićevega modela Slovenian-LLM-eval-v0, in sicer so izboljšali prevode. V zbirki so poslovenjeni testi ARC Challenge, ARC Easy, BoolQ, HellaSwag, NQ Open, OpenBookQA, PIQA, TriviaQA in Winogrande.
Angleški izvirnik so prevajali podobno kot Gordić, in sicer so GPT-4 dali poleg izvirnika še strojni prevod z Google Translatom v slovenščino in ga prosili za izboljšavo prevoda. Poziv (prompt), ki so ga uporabili, je jasno definiral, kaj želimo od GPT-4. Rezultat je testna zbirka za preverjanje slovenskih jezikovnih modelov.
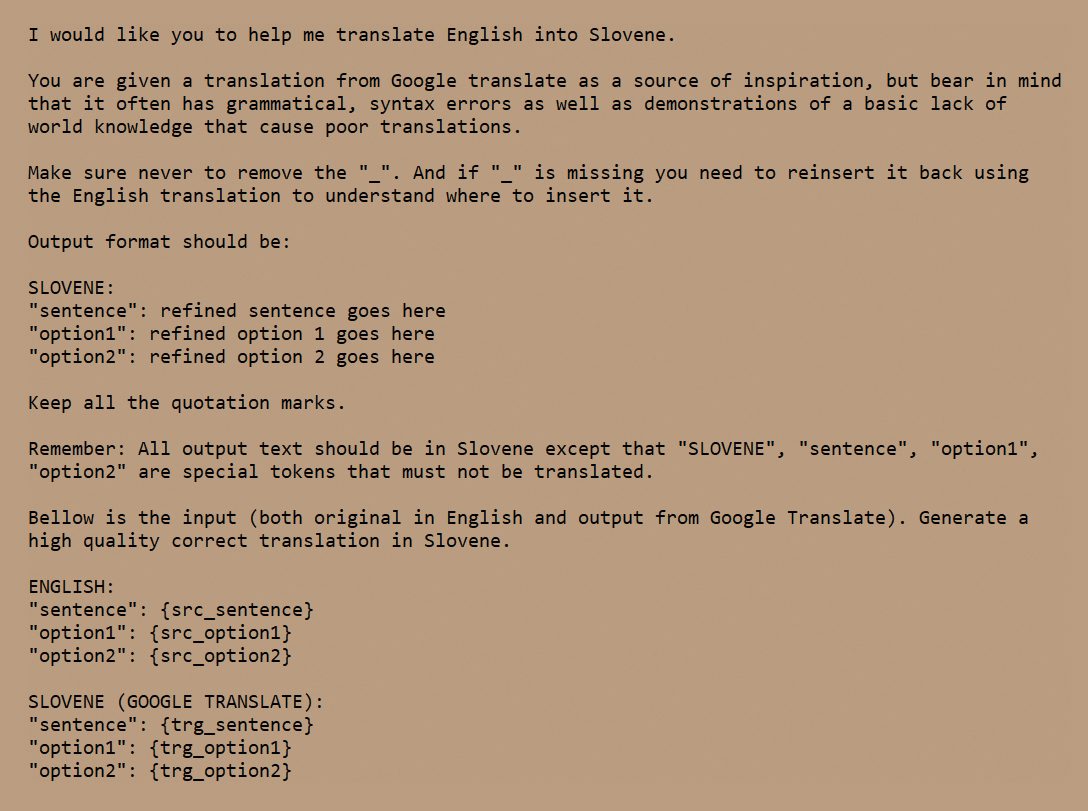
Poziv, ki so ga na CJVT uporabili za refiniranje prevodov za izdelavo testne zbirke za preverjanje zmogljivosti jezikovnih modelov v slovenščini, Slovenian-LLM-eval.

Izsek iz testne zbirke Slovenian-LLM-eval.
Kot je pojasnil ob tem, je najtežji del ocena oziroma testiranje modela, saj niti za slovenski niti za srbski jezik ni dobrih standardiziranih preizkusov (LLM eval), zato je ustvaril svoja. Postopek je sorazmerno razumljiv. Najprej je poiskal angleške preizkuse, ki jih ni malo. Na koncu se je odločil za naslednje Hellaswag, Winogrande, PIQA, OpenbookQA, ARC-Easy, ARC-Challenge (logično sklepanje), NaturalQuestions, TriviaQA (znanje o svetu) in BoolQ (bralno razumevanje). Nato je preizkusil več strojnih prevajalnikov in se odločil za najboljšega, s katerim je prevedel naloge na teh preizkusih. Izkazalo se je, da je Google Translate najprimernejši. Na koncu je prevode izboljšal z modelom GPT-4 ter jih preveril še s človeškim strokovnjakom – to je bil Nikola Ljubešić, ki je zaposlen v Laboratoriju za kognitivno modeliranje na Institutu Jožef Stefan v Ljubljani. Vsi Gordićevi izdelki – SlovenianGPT, yugoGPT, Slovenian-LLM-Eval-v0 in Serbian-LLM-Eval-v1 – so dostopni na njegovem profilu na Hugging Faceu.
TinySLlama
Na koncu omenimo še najmanjši model, ki teče tudi na pametnem telefonu. Tomaž Savodnik, nekdanji urednik revije Moj Mikro in za kratek čas sourednik Monitorja, danes pa direktor za informatiko v Valiconu, je razvil svoj model s simpatičnim imenom TinySLlama, ki smo ga tudi preizkusili.
Model, ki trenutno še ni javno dostopen, temelji na izhodiščnem modelu TinyLlama, ki je pomanjšana različica Metine LLaMe. Savodnik je model uril na korpusih MaCoCu, mC4 in slovenski Wikipediji, ki so skupaj dali okrog osem milijard koščkov besed. Model ima milijardo parametrov, torej enako mnogo kot GaMS, in je sicer na voljo v obliki klepetalnika, a ima nekaj omejitev. Glavna je, da ni bil urjen za pogovor s podvprašanji, zato se ob postavljanju nadaljnjih vprašanj pogosto zmede – bolje ga je vsekakor vprašati nekaj od začetka brez predhodnega pogovora.
Model tudi nima samokritike in bo ob vprašanjih, na katere ne pozna odgovora, navajal neresnice. Naš urednik dela v Neuralinku, avtor tega prispevka pa je računalniško-informacijski znanstvenik in bloger, če bi verjeli TinySLlami. Ker ni bil moderiran, je ključni trik, kako mu postavljati vprašanja, da bodo odgovori smiselni. Z nekaj vaje se to da doseči, zavedati pa se moramo, kaj sploh lahko ve.
Seveda model ni primerljiv z GPT-4, a to niti ni bil namen. Je namreč veliko manjši in teče na eni sami grafični kartici Nvidia A2, v prihodnosti pa je načrtovan še manjši model, ki bo tekel kar na običajnih telefonih. V spletnem vmesniku sta združena jezikovni model in model za sintezo govora, zato lahko TinySLlama tudi glasovno odgovarja na poizvedbe. Včasih ustreli kakšnega kozla, a za preprosta vprašanja in dopolnjevanje besedil deluje solidno. Izpolnjevanje ukazov pa mu gre slabše, ker to ni bil nikoli njegov namen.
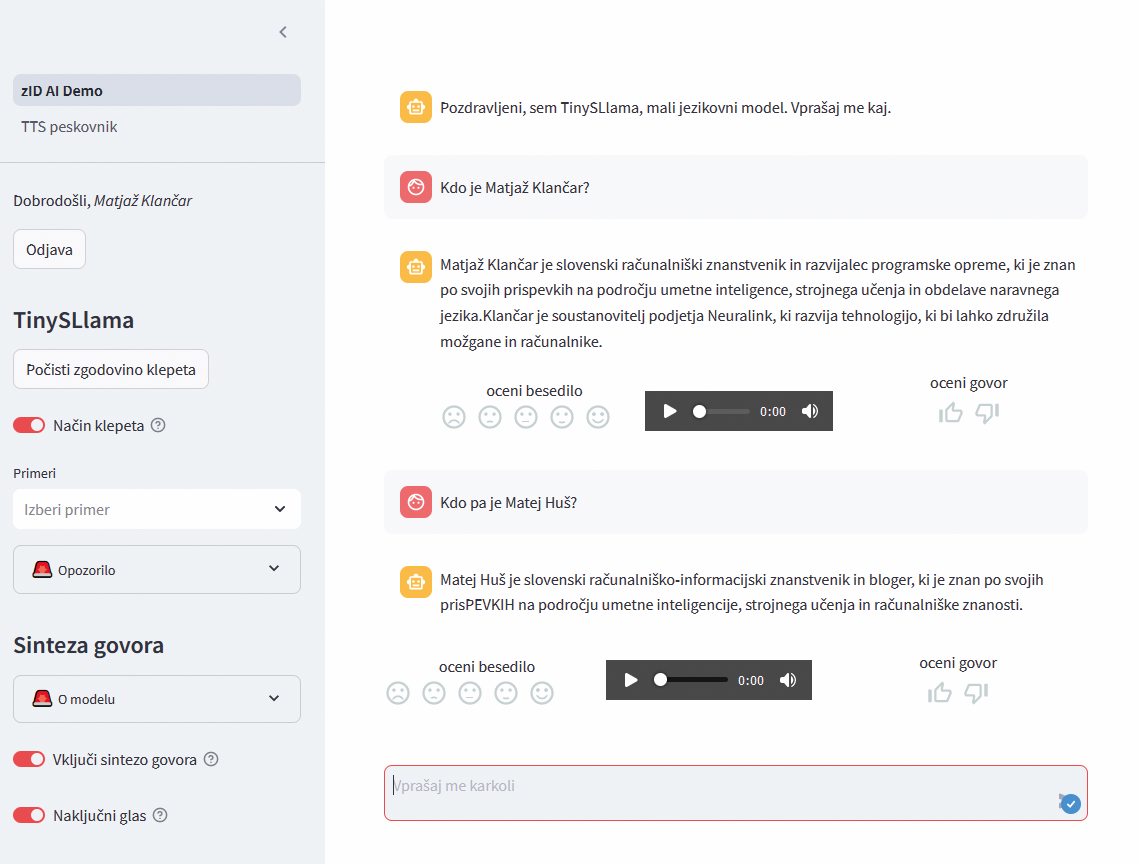
TinySLlama je jezikovni model za slovenščino, ki ga je razvil Tomaž Savodnik. Kadar odgovor pozna, odgovori pravilno, sicer pa improvizira – včasih brcne precej v temo.
Modelov bo čedalje več
Priprava jezikovnega modela od začetka, brez temeljev v obstoječih arhitekturah, je zelo težak problem. Popolnoma drugače pa je, če začnemo z dobrimi tujimi modeli, denimo LLaMa. Tudi v tem primeru naloga ni trivialna, a je izvedljiva že s strojno opremo, ki je na voljo sleherniku, ki se – če nekoliko pretiravamo – tega lahko loti tudi v popoldanskem času. Za zdaj imamo tri družine slovenskih modelov in pričakovati je, da bomo v prihodnosti dobili tako več družin kot tudi več predstavnikov znotraj posamezne družine, ki bodo prilagojeni točno določenim funkcijam. Verjetno bo modelov več, kot jih bo dejansko uporabnih, a s tem ni nič narobe. Tudi z gradnjo modelov se vzpostavlja pomembno znanje, ki ga bomo še kako potrebovali, tako kot tudi kakovostne vire besedil v slovenščini, ki bodo služili kot učno gradivo. Tu človeška pamet še ni zamenljiva, saj so britanski raziskovalci letos julija v Nature poročali, da učenje modelov na vsebinah, ki so jih ustvarile prejšnje generacije modelov iste družine, vodi v incestuozni kolaps modelov, ki na koncu le še blebetajo nerazumljive zloge.
Intervju - Tomaž Savodnik, avtor jezikovnega modela za slovenščino TinySLlama

Veliki jezikovni modeli govorijo tudi slovenščino in sorazmerno dobro prevajajo vanjo in iz nje. Čemu ste se odločili za izgradnjo svojega jezikovega modela v slovenščini? Kdaj je dozorela ideja o malem jezikovnem modelu?
V okviru Zavoda za informacijsko družbo (ZID) se v povezavi s projektom preberi.si že zelo dolgo ukvarjam z aplikativnimi raziskavami in razvojem različnih jezikovnih tehnologij. V zadnjem obdobju te tehnologije intenzivno uvajamo in preizkušamo tudi v podjetju Valicon (kjer je Tomaž zaposlen, op. p.). Generativni jezikovni modeli so pritegnili izjemno pozornost javnosti, a večinoma delujejo najbolje v angleščini. Tudi na vprašanja v slovenščini so dostopne različice večinoma odgovarjale v angleščini, le s težavo si lahko model prepričal, da je to počel v slovenščini. Mnogi tuji eksperimenti so nakazovali, da je z dodatnim usposabljanjem take modele mogoče prilagoditi in bistveno izboljšati za uporabo v drugem jeziku. Zaželel sem si modela, ki bi vedno odgovoril v čim bolj »tekoči« slovenščini. Konec lanskega leta me je znanec opozoril na projekt PoVeJMo, ki si je zadal podoben cilj. Bil sem nestrpen in nisem bil pripravljen čakati do avgusta, ko je bil napovedan izid modela z eno milijardo parametrov (GaMS-1B, op. p.). Po nekaj neprespanih nočeh sem se odločil tak model narediti sam.
Model ste poimenovali TinySLaMa, kar namiguje na njegovo provenienco.
Model TinySLlama temelji na izhodiščnem modelu TinyLlama. Gre za prilagojeno, pomanjšano, arhitekturo modelov Meta Llama 2. Njihovi avtorji so želeli razviti model od samega začetka, ki bi bil primeren za uporabo z omejenimi strojnimi viri, denimo na pametnem telefonu. Konec lanskega leta so objavili nadzorno točko (checkpoint) osnovnega modela, ki je do takrat v procesu strojnega učenja obdelala že 3.000 milijard koščkov besedila (token). Ta model sem ocenil kot primerno izhodišče za proces prilagajanja slovenščini ter ga uporabil.
Po eni strani dajejo umetna inteligenca in veliki jezikovni modeli vtis čarovnije, po drugi strani pa ves čas poudarjamo, da lahko skoraj vsakdo prilagodi obstoječe modele. Kako težko je torej ustvariti tak model in koliko znanja o delovanju umetne inteligence ter splošne programerske pismenosti potrebujemo?
V teoriji je precej preprosto. Vzamemo primeren osnovni model ter čim večji obseg besedil v slovenščini in nadaljujemo učenje za osnovno nalogo modela. Pri tovrstnih modelih je to napoved naslednjega koščka besedila glede na dosedanje besedilo. To stopnjo imenujemo nenadzorovano učenje (unsupervised learning) oziroma v našem primeru nadaljevanje nenadzorovanega učenja. Da ustvarimo model, ki upošteva navodila ali smiselno klepeta, osnovni model prilagodimo z dodatnim učenjem na osnovi zbirke primerov izpolnjevanja ukazov ali klepeta. To drugo fazo imenujemo nadzorovano učenje (supervised learning). Tej fazi lahko sledijo še različne druge faze prilagajanja modela.
V praksi takšno splošno razumevanje delovanja jezikovnih modelov pogosto ne zadošča. Če želimo proces in parametre učenja prilagoditi razpoložljivim virom, je pomembno podrobno preučiti poročila o podobnih eksperimentih. Upoštevati je treba tako obseg učnih zbirk besedila kot tudi razpoložljivost strojne opreme oziroma računske moči ter seveda čas, ki ga imamo na voljo. Za uskladitev vsega naštetega in parametrov učenja je koristna dobra intuicija glede delovanja modelov in strojne opreme. Učimo se iz napak, najraje tujih. Seveda obstaja mnogo odprtokodnih rešitev, ki celo uporabnikom brez izjemnih spretnosti kodiranja ali razumevanja arhitekture jezikovnih modelov omogočajo eksperimentiranje.
Bo torej v prihodnosti lahko vsakdo ustvarjal svoje modele?
Ustvarjal jih verjetno ne bo vsakdo, ker to niti ne bo potrebno. Hkrati bi bilo to ob trenutnih arhitekturah in s trenutno tehnologijo nepredstavljivo drago ter zamudno. Prilagajanje obstoječih modelov lastnim potrebam in nalogam pa bo v prihodnje zagotovo postalo še bolj dostopno in preprosto.
Model vsebuje milijardo parametrov. Kolikokrat več besedil oziroma koščkov besedila (token) pa je vsebovalo gradivo za njegovo urjenje? In kje ste to gradivo zbrali?
Model je med nadaljnjim usposabljanjem za slovenščino videl okoli osem milijard koščkov slovenskih besedil. Ker je večji del zbranih ter obdelanih slovenskih korpusov dostopen izključno uradni akademsko raziskovalni skupnosti, sta zbiranje in izbiranje primernega obsega besedil predstavljala eno večjih zagat za izvedbo projekta. Levji delež besedil tako izvira iz prostodostopnih korpusov MaCoCu, mC4 in seveda slovenske Wikipedije. Še več aktualnih ter raznovrstnih besedil bi modelu zagotovo koristilo.
Projekt PoVeJMo se je problema lotil tako, da so javnost preprosto prosili, naj na spletno stran naložijo še dodatna, svoja besedila.
Zelo razumem in podpiram prizadevanja projekta Povejmo, da bi zbrali bistveno več slovenskih besedil. Še bolj goreče pa bi projekt zagovarjal, če bi lahko upal, da bodo tako zbrana besedila na voljo vsem, torej tudi za izboljšavo modelov, kakršen je moj.
Na hitro sem izračunal, da sem v svoji karieri za Monitor napisal okrog 50 milijonov znakov. Bi se iz tega dalo narediti model, ki bi pisal kot jaz?
Brez spodobnega osnovnega modela, ki je že prepoznal specifike semantike in sintakse slovenskega jezika, to ni mogoče. Za prilagoditev sloga pisanja pa bi modelu, ki je že naučen slovenščine, najverjetneje zadoščala že bistveno manjša količina reprezentativnih besedil. Generativni jezikovni modeli so se namreč v praksi izkazali za zelo učinkovite pri učenju na podlagi peščice primerov.
To še zdaleč ne pomeni, da bi tak model zmogel »miselni proces«, ki je omogočil vse napisane prispevke. Za slog uporabe jezika in besedišča pa bi tak obseg najverjetneje zadoščal. Za kaj več bi se moral model naučiti »brati med vrsticami« in imeti vpogled v vsa dejstva in okoliščine, ki so bili osnova zapisanega prispevka, pa naj bo to kolumna, recenzija ali vest. Moral bi razumeti, zakaj je avtor posameznemu dejstvu posvetil več pozornosti kot drugemu, zakaj je ubesedil vrednostno sodbo na zapisan način. Obstajajo hipoteze, kako bi lahko prišli do takih modelov, a samo zato, ker bi morda mogli, še ne pomeni, da bi tudi smeli.
Jezikovni modeli zmorejo početi svari, katerih posledic še ne znamo dobro predvideti. A hkrati je duh ušel iz steklenice, modeli so tu, pripravi jih lahko skoraj vsakdo.
Vse pogosteje se vprašam, kaj bi o trenutni svetovni situaciji porekel Jurij Gustinčič, a v splošnem se strinjam z mnenjem Marka Milosavljevića, da potencialne zmožnosti tehnologije odpirajo vrsto moralnih in etičnih dilem. Menim pa, da medtem ko strokovnjaki za moralo in etiko razpravljajo o teh izzivih, verjetno ne bo večje škode, če jezikovne modele naučimo, da slovenski jezik pozna dvojino.
Kako hitro jih torej to naučimo? Koliko časa traja trening modela TinySLlama in kakšno računsko moč je potreboval?
Končni model TinySLlama je za celoten proces potreboval okoli 400 ur grafičnih procesorjev. Uporabljena oprema je bila odvisna od trenutne razpoložljivosti in cene ponudbe različnih ponudnikov najema opreme in ni bila vedno optimalna. Ker gre za dokaj majhen model, je bilo z ustreznimi nastavitvami učenje mogoče izvajati tudi na zmogljivih potrošniških modelih grafičnih kartic tipa Nvidia RTX 3090 ali 4090 s 24 GB pomnilnika, ki so dosegljivi tudi domačim uporabnikom. Namesto da bi nekaj tednov igrali igre, bi lahko tak model torej naredili tudi na domačem računalniku.
Za učenje jezikovnih modelov sta z vidika strojne opreme poleg zmogljivosti grafičnega procesorja ključni velikost in hitrost pomnilnika VRAM. Če imate na voljo 64 GPU, lahko vse skupaj opravite v nekaj urah, a pri distribuiranem učenju modela postane izziv sinhronizacija procesov in stanj.
Rezultat je torej TinySLlama. Če bi jo morali čim bolje spromovirati - v čem je boljša od velikih jezikovnih modelov tujih igralcev, ki so se slovenščine priučili mimogrede?
Majhnost in koherentnost generiranega besedila v slovenščini sta zagotovo pomembni lastnosti tega modela. Uporabiti bi morali bistveno večji in zmogljivejši jezikovni model, da bi bilo slovensko generirano besedilo vsaj približno tako tekoče in brez vrinjenih tujih besed. Tudi taki modeli obstajajo; konec koncev je prosto dostopna tudi Llama 3.1 s 405 milijardami parametrov. A takega modela ne morete uporabljati in z njim izvajati eksperimentov na domačem računalniku.
TinySLlama je v primerjavi s ChatGPT, z Mistralom ali Geminijem žepna različica, kar pa ima svoje prednosti.
TinySLlama je majhen model in zato z vidika potrebne računske moči poceni in hiter za uporabo, tudi v lokalnem okolju. Majhnost modela hkrati pomeni omejitev pri nalogah, ki bi zahtevale kompleksno sklepanje ali priklic nekaterih dejstev. Morda najpomembnejša razlika, ki ni nujno prednost, je lastnost modela, da vedno odgovarja v slovenščini. Tudi če mu vprašanje zastavite v angleščini, bo model odgovoril v slovenščini. Preizkusi so pokazali, da lahko modelu posredujemo srbsko besedilo v cirilici in odgovoril bo s povzetkom besedila v slovenščini.
Kljub majhnosti je na testu slovenščine model med najboljšimi in premaga tudi nekatere večje.
Ker je videl več besedil v slovenščini, ima model boljšo predstavo o odtenkih jezika. Bolje »razume« nalogo in generirano besedilo je boljši približek pričakovanega odgovora pri nalogah, ki ne smejo zahtevati kompleksnega sklepanja. Večji ali bolje rečeno globlji modeli na obstoječih testih trpijo predvsem zaradi pomanjkljive sposobnosti ustvarjanja v slovenščini. S prilagoditvijo za slovenščino bi tudi večji modeli dosegali bistveno boljše rezultate.
Kako pa to merimo? Aleksa Gordić, ki je ustvaril enega večjih slovenskih modelov, je ugotovil, da je vrednotenje modelov s poudarkom na slovenščini pomanjkljivo rešen problem, saj sploh ni standardiziranih testov.
To je dobro in izredno pomembno vprašanje. Težave primerjalnih testov so mnoge in mnogotere, od vsebinskih in metodoloških do povsem tehničnih. Prvi in ta hip edini tovrstni test, ki je prilagojen za generativne jezikovne modele v slovenščini, je slovenian-llm-eval. Aleksa Gordić je s pobudo in koordinacijo priprave tega testa ter z njegovo javno objavo ogromno prispeval, čeprav sam sploh ne govori slovensko. Brez tega razvoj modela TinySLlama ne bi bil mogoč. Brez merskih instrumentov, četudi pomanjkljivih, je kot bi slep in gluh sredi Alp iskal pot do morja: pri Sedmerih jezerih ali v najboljšem primeru pri Bohinjskem jezeru bi ves potolčen mislil, da si dosegel cilj.
Bomo dobili še kakšen test za slovenske modele? Ste razmišljali, da bi ga razvili sami?
Tudi projekt PoVeJMo si prizadeva to testno zbirko in kodo nadgraditi in upajmo, da jim bo v kratkem uspelo. A s tem še zdaleč ne bodo rešeni vsi izzivi, saj gre le za prevode primerljivih angleških testov. V njih ni kulturološko pogojenih dimenzij.
Z idejo razvoja referenčnega testa za generativne jezikovne modele sem se pred časom obrnil na Državni izpitni center. Zdelo se mi je logično, da je institucija, ki je referenčna za nacionalne preizkuse znanja, najprimernejša tudi za preizkuse znanja za umetno inteligenco, navsezadnje tudi razpolagajo z zajetno zbirko strokovno pripravljenih in preverjenih nalog. A pri tem sem povsem prezrl dejstvo, da si nalog in ciljev državne ustanove ne zastavljajo same. Kljub temu je bilo srečanje poučno in odnos zelo korekten.
Upam, da bo v prihodnosti na ustrezni ravni vzpostavljena koordinacija, ki bo učinkovito identificirala in povezala vse, ki bi lahko prispevali znanje, vsebino in tehnologijo, da dobimo tak referenčni test. Ta interdisciplinarni izziv presega kompetence posamezne fakultete ali ministrstva.
Če se vrneva k vašemu modelu TinySLlama … Ta v nekaterih vidikih še šepa, njegovi odgovori so včasih nesmiselni ali napačni. Boste razvoj nadaljevali?
Model ne šepa le v nekaterih, temveč v mnogih pogledih, kar pa je pričakovano. Za klepet oziroma dialog model sploh ni videl učnih vzorcev, a mu kljub temu občasno uspe. Če med klepetom želite zamenjati temo pogovora ali se vaše vprašanje navezuje na oddaljeno vsebino, vas bo skoraj zagotovo presenetil s povsem nesmiselnim odgovorom. Mnogo bolje se odreže pri odgovoru na prvo vprašanje, a tudi tu so področja in tipi vprašanj, kjer bo nakladal, da se bo kar kadilo. Vse to so izkušnje, ki bi z veliko dela lahko pripeljale do boljših učnih množic in modelov.
Kaj pa dostop do spleta v realnem času?
Model, ki bi omogočal uporabo orodij, kot so spletno iskanje, kalkulator in podobno, skratka vpogled v zunanji vir podatkov, je konec koncev še vedno le jezikovni model, ki pa se je na ustrezni učni množici naučil prepoznati, kdaj bi bilo za ustrezen odgovor treba uporabiti zunanji vir podatkov. Arhitektura modela TinySLlama za to sicer ni najprimernejša, a ključna ovira je ustrezna učna množica v slovenščini.
Letos smo poleg vašega dobili še dva jezikovna modela za slovenščino. So to znanilci nove dobe in se jih obeta še več?
Nekaj zagotovo. Večji in bolj specializirani so v časovnici projekta PoVeJMo predvideni na začetku prihodnjega leta. To so tudi edini, za katere lahko upravičeno pričakujemo, da bodo javno dostopni. Že ta hip ni večjih ovir za prilagoditev osnovnega modela SlovenianGPT za izpolnjevanje navodil ali klepetanje. Tak model je izdelal Aleksa Gordić, svojo različico sem naredil tudi sam in tudi v okviru projekta Povejmo so pripravili svojo različico. Če bi že bila javno dostopna zbirka medicinskih dialogov in ukazov, bi tako lahko naredili precej zmogljiv model, prilagojen za to področje. Prepričan sem, da bi lahko do konca letošnjega leta videli še par različnih modelov, morda celo kakšnega manjšega.
Pa ima sploh smisel graditi slovenske modele, če veliki modeli velikanov govorijo čedalje več jezikov vedno bolje?
Smiselno vsekakor je, morda celo prav zato, ker so modeli velikanov vse boljši in ne kljub temu. Ali je tudi ekonomsko vzdržno, je drugo vprašanje. Odvisnost od modelov kot storitev lahko vodi v izpostavljenost podatkov. To tveganje ni sprejemljivo v vseh situacijah. Pričakovati, da bodo velikani svoje modele večno delili s svetovno skupnostjo, pa je vsaj naivno. Zadnja objava podjetja Meta družine modelov Llama 3.2 je morda najboljši dokaz, da se lahko podjetja enostransko odločijo, da delu sveta uporabe svojih modelov ne bodo dovolile. Če se bo ta igra moči med EU in velikani nadaljevala, je mogočih scenarijev več.
Bistveno je torej, da krepimo znanje ter sposobnosti na tem področju. Kritična masa tega znanja v Sloveniji je namreč dobesedno kritična, saj strokovnjakov s takimi kompetencami primanjkuje povsod. Z nacionalne perspektive je daleč najpomembnejše ustvarjanje kakovostnih učnih virov, torej vsebine. Kaj od tega in kdaj bo prosto dostopno, bo najverjetneje določal javni interes oziroma njegova opredelitev v raznih razpisnih pogojih ter v zakonodaji.
Če skleneva s pogledom nazaj in naprej. V preteklosti ste počeli marsikaj, od urednikovanja Mojega mikra in celo sourednikovanja Monitorja do uspešne zgodbe email.si in danes podatkovnih analiz v podjetju za tržne raziskave. Kakšni pa so načrti za prihodnost in ali vključujejo umetno inteligenco?
Podobno kot v časih Mojega mikra in email.si tudi danes hiter tehnološki razvoj dnevno osvetli nove aplikativne priložnosti ali drugačno perspektivo za stare izzive. Razdelanih idej za nadaljnje raziskave in razvoj je tako več kot ur v dnevu. Tudi v tržnih raziskavah, s katerimi se ukvarjamo v Valiconu, so priložnosti za generativne jezikovne modele, a še zdaleč ne zgolj za to vrsto modelov. Zasebno bi želel še izboljšati model za sintezo govora v slovenščini, ki sicer dela že precej dobro. Pri generativnih jezikovnih modelih bo zagotovo sledil večji, a verjetno pred njim še manjši. Prihajajoča SLamica bo imela 500 milijonov parametrov in bo delovala lokalno, na telefonu.