Javni servisi za slovenščino
Za uradno zvenečim naslovom se skriva kopica koristnih orodij, ki segajo od slovarjev prek korpusov do pravih digitalnih pomočnikov, ki so jih slovenski raziskovalci razvili za nas – uporabnike slovenskega jezika. Na ljubljanski univerzi deluje Center za jezikovne vire in tehnologije, ki danes skriva pravo zakladnico orodij, za katera večina sploh še ni slišala. Danes bomo to spremenili.
Center za jezikovne vire in tehnologije nudi obilico pripomočkov za delo s slovenskim jezikom.
Večkrat smo že pisali o najrazličnejših digitalnih ali elektronskih orodjih, zbirkah in pomočnikih pri uporabi slovenščine, za kar obstaja dober razlog. Niti po številu govorcev niti po količini in kakovosti orodij za uporabnike slovenščina ni majhen ali deprivilegiran jezik, temveč sodi med digitalne velikane. Pisali smo že o velikem projektu Raba slovenščine v digitalnem okolju (RSDO) in orodjih, ki so nastala v tem projektu (Slovenščina v digitalnem svetu, Monitor 5/23), o izdelkih podjetja Amebis, ki so se prebili že v zgodnje različice Microsoftove pisarne (Slovenski David proti ameriškim Goljatom, Monitor 6/24), bogatem naboru slovarjev, korpusov in popravljalnikov jezika (Brez lektorjev in prevajalcev, Monitor 7-8/23), o (zdaj že zastarelih) tehnologijah za strojno branje (Od Govorca do Bralca, Monitor 1/18), strojnem razpoznavanju govorjene slovenščine, ki se v praksi že uporablja na sodiščih (Umetna inteligenca na slovenskih sodiščih, Monitor 2/24), in njegovih začetkih (Razumeti slovensko, Monitor 1/09) ter današnjem stanju (Stran s tipkovnico, računalniku narekujmo!, Monitor 1/24). Večkrat smo tudi preizkusili različne prevajalnike in ugotovili, da so veliki jezikovni modeli dokončno poskrbeli, da jih smemo razglasiti za široko uporabne. Slovenščina morda res ni velikan, je pa povsem enakovreden evropski jezik z ogromno infrastrukturo in vrsto izobraženih strokovnjakov, ki so nam precej olajšali življenje.
Opisana orodja, če ni izrecno poudarjeno drugače, najdete na vstopni strani www.cjvt.si in več podstraneh.
Velik del teh strokovnjakov je zbranih tudi v Centru za jezikovne vire in tehnologije (CJVT) Univerze v Ljubljani, ki fizično gostuje na računalniški fakulteti, vsebinsko in kadrovsko pa se razprostira prek šestih članic, in sicer še filozofske, pedagoške, elektrotehniške fakultete, fakultete za upravo in fakultete za družbene vede. V CJVT je torej vključenih več deset laboratorijev in še precej več raziskovalcev z različnih fakultet, ki so razdrobljeni po prestolnici. Formalno torej večina raziskovalnih projektov, ki se ukvarjajo z digitalizacijo in s slovenščino, teče na CJVT. Orodja, ki nastajajo z davkoplačevalskimi sredstvi, so načelno odprta in dostopna vsakomur, ki jih želi uporabiti, zato je koristno, da jih poznamo.
Tega se zavedajo tudi na CJVT, ki ga vodi Simon Krek z ljubljanske fakultete za računalništvo in informatiko. Letos so se zato lotili prenove spletnih strani, da lahko uporabniki na enem mestu dostopijo do vseh njihovih javnih storitev, ki so namenjene lažjemu ustvarjanju v slovenskem jeziku. Uporabniki torej vidimo zlasti orodja, ki jih CJVT za nas pripravlja, na drugi strani – torej v centru – pa potekajo razvoj (raziskovalne in infrastrukturne aktivnosti), organizacija konferenc, kongresov in drugih dogodkov, sodelovanje v projektih, izobraževanje in usposabljanje itd. Hkrati so prisotni tudi na družbenih omrežjih.
Kaj je kaj
V grobem lahko orodja razdelimo v več kategorij. Slovarji so seznami besedi, ki se pojavljajo v jeziku oziroma določenem polju, skupaj z razlago in dodatnimi informacijami. V korpusih so ogromne količine gradiva, ki kaže dejansko rabo jezika in omogoča različne analize ter uvide. Servisi pa izvajajo različne operacije, denimo v besedilu iščejo sopomenke, postavljajo vejice, popravljajo skladnjo, poenostavljajo, zapisujejo govorjeno besedilo, ga prevajajo, nudijo računalniški izgovor zapisanega besedila itd.
CLARIN
CLARIN (Common Language Resources and Technology Infrastructure) je evropska digitalna infrastruktura, ki omogoča enostaven in trajnosten dostop do jezikovnih podatkov in orodij, ki se uporabljajo v raziskavah v humanistiki in družboslovju. V distribuirani digitalni infrastrukturi sodeluje več centrov iz Evrope, med katerimi je tudi slovenski CLARIN.si.
CLARIN je bil ustanovljen leta 2012 kot ERIC (konzorcij evropske raziskovalne infrastrukture), ki jih je omogočila Evropska komisija leta 2009 in so odtlej vzniknili v različnih raziskovalnih vedah. Slovenski nacionalni konzorcij zagotavlja jezikovne vire, tehnologije, strokovno podporo in prenos znanja. Srce predstavljata repozitorij CLARIN.se in agregator VLO, na voljo pa so še različni konkordančniki (programski vmesnik za iskanje po korpusih) in več storitev (CLASSLA-Stanza, ReLDIanno, repozitoriji na GitHubu in GitLabu, WebAnno, JOTA, SENTA in Korpusnik). Te storitve najdemo tudi na straneh CJVT.
Ta orodja so na voljo v treh oblikah, odvisno od potreb in smiselnosti. Ponavadi imajo spletni vmesnik, ki je dostopen kot običajna spletna stran, s katero interagiramo v brskalniku. Za nekatera orodja je z vidika avtomatizacije in vključitve v druge izdelke smiseln dostop prek API. Pogosto pa je v repozitoriju Github dostopna tudi celotna koda skupaj z zbirko podatkov. V tem prispevku bomo pogledali, katera orodja CJVT nudi danes in nekaj projektov, ki bodo v prihodnosti dali še dodatna.
Vire, ki jih ponuja CJVT, najdemo na spletni strani viri.cjvt.si/slv/. Razdeljeni so na slovarske, korpusne in oblikoslovne. Vsi uporabljajo enak spletni vmesnik, zatorej lahko iščemo po vseh skupaj ali pa po posameznih virih posebej, odvisno od potreb. Obstaja tudi angleška različica strani, ki pa, roko na srce, ni posebej uporabna, ker so prevedeni le elementi vmesnika, medtem ko vsebina virov seveda ni mogla biti. Še nekatera druga orodja so na voljo na www.cjvt.si/viri-in-orodja/, denimo leksikoni, konkordančniki itd.
Slovarji
Slovarska vira sta slovarja Kolokacije (Kolokacijski slovar sodobne slovenščine), ki vsebujejo 4,5 milijona kolokacij in 81 tisoč iztočnic, in Sopomenke (Slovar sopomenk sodobne slovenščine) s 14,5 milijona zgledov, 100 tisoč iztočnic in 362 tisoč sopomenk. Oba nosita oznako 2.0 in sta bila nazadnje posodobljena konec leta 2022, kar je v jezikoslovju – sodobno. Podatki, ki ju napajajo, so dostopni v repozitoriju CLARIN.si.
Nacionalni konzorcij CLARIN.SI je del evropske raziskovalne infrastrukture.
Kolokacije so ustaljene ali vsaj značilne sopojavitve besed, zato so njihovi slovarji pomembni pri analizi jezika, produkciji in usvajanju. Tak primer je besedna zveza grenak priokus, a iskanje po iztočnici priokus razkrije še celo vrsto bolj ali manj pogostih sopojavitev. Priokus je lahko slab, trpek, rahel, neprijeten, poznamo kanček ali ščepec priokusa. Priokus lahko imamo, pustimo, dobimo, dajemo, dodamo, čutimo, popravimo, povzročimo, odplaknemo itd. Slovar kolokacij prikaže vse te različne kombinacije, ki jih razporedi po besednih vrstah (samostalniki, predlogi, pridevniki itd.). Če pogledamo geslo pomnilnik in vidimo, da slovar pozna vse od vodila in pomnilnika (termin memory bus) do skoparjenja s pomnilnikom (lepo tvorjena slovenska besedna zveza). Slovar sodi med odzivne, torej nikoli ni zares zaključen. Tak slovar se odziva na spremembe v jeziku sproti, hkrati pa sestoji tudi iz neprečiščenih (samodejno pridobljenih) podatkov. Vsa gesla v njem so razvrščena v tri skupine: samodejno pridobljene kolokacije, delno pregledana gesla in kolokacije (ročno členjene in pregledane). Uporabniki pa lahko ustreznost tudi ocenjujejo.
Tesno povezan je slovar Sopomenke, ki vsebuje prav te. Slovar je nastal s podatki iz več zbirk, vsi vnosi pa vsebujejo povezavo do pojavitev v korpusu Gigafida 2.0. Podatki so se vanj izluščili z računalniškimi metodami, manjši del pa je tudi ročno pregledan. Sopomenki za pomnilnik sta shramba in spomin, za hišo pa precej več, od poslopja in stavbe pa do razmajane koče in bajturine. Sopomenke se namreč pomensko redko popolnoma prekrivajo. Poleg sopomenk slovar navaja tudi protipomenke, kjer te obstajajo. Temeljna vira za slovar sta korpus Gigafida in DZS-Oxfordov veliki angleško-slovenski slovar. Podatke v virih so prežvečili računalniki in z algoritmom PageRanke (da, to je tisti algoritem, ki ga je izumil Google) izdelali grafe sopojavitev. A slovar ni nikoli zaključen in predloge lahko dodajajo tudi vsi uporabniki. Četudi predlog ni vključen v slovar, bo ostal viden v vmesniku.
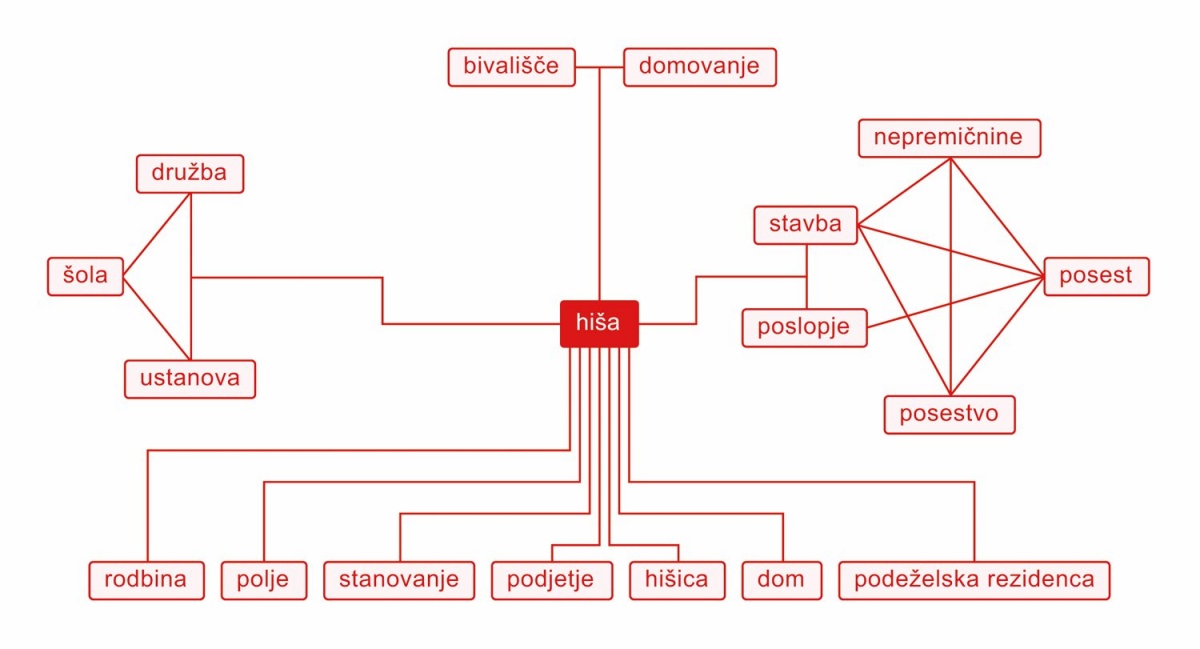
Sopojavitveni graf za iztočnico hiša. Slika: CJVT (CC BY-SA 4.0)
Korpusi
Med javnimi servisi CJVT sta korpus pisne standardne slovenščine Gigafida 2.0 in korpus govorjene slovenščine Gos 2.0. Prvi sodi med stare znance, saj je druga različica zaživela že leta 2019. Prva različica iz leta 2012 je vsebovala slovenščino, kot se je tedaj zapisovala, torej tudi nestandardne oblike. Prva Gigafida je skupaj s še nekaterimi korpusi (Kres ter podkorpusa ccGigafida, ccKres) nastala v okviru projekta Sporazumevanje v slovenskem jeziku med leti 2008–2013. Naslednica, ki je nastala v projektu med 2015–2018, pa je prečiščena in vsebuje le standardni jezik. Odstranili so podvojene dele in fragmente, poskrbeli pa so še za boljšo pokritost oziroma reprezentativnost. V njej je danes 38 tisoč besedil in 1,1 milijarde besed, ki prihajajo iz časopisov (47,8 odstotka), interneta (28 odstotkov), revij (16,5 odstotka), stvarnih besedil (3,8 odstotka), leposlovja (3,5 odstotka) in od drugod (0,3 odstotka). Besedila so tokenizirana in stavčno segmentirana, oblikoskladenjsko označena in lematizirana.
Če vtipkamo pomnilnik, dobimo skoraj 20 tisoč konkordanc, ki so večinoma iz revij in časopisov, manjši del pa z interneta in iz stvarnih besedil. A deset pojavitev je tudi iz leposlovja, denimo: »In v glavo so ji vsadili neke merilne reči in pomnilnike, dali so ji tudi zdravila.« (Ruski disko, Wladimir Kaminer, 2005.) Obstaja pa tudi korpus Gigafida 2.0 Proto, ki ni deduplicirana.
Manj poznan je korpus govorjene slovenščine Gos 2.1, ki vsebuje okoli 320 ur posnetkov pogovorov v različnih situacijah. Nastal je z združitvijo korpusov Gos 1.1, Videolectures in govorne zbirke Artur. Gre za sodobno slovenščino, saj so bili pogovori posnetki v obdobju 2007–2022. Na posnetkih, ki obsegajo radijske in televizijske oddaje, šolske ure, delovne sestanke, zasebne pogovore in podobno, je dva milijona besed. Vsi posnetki so tudi zapisani (transkribirani) v dveh oblikah: standardizirani in pogovorni. Iskanje je mogoče tudi prek konkordančnikov NoSketchEngine in Kontext, ki sta del infrastrukture CLARIN.si.
Oblikoslovje
Oblikoslovni leksikon CJVT se imenuje Sloleks 2.0. V njem je sto tisoč iztočnic, ki imajo pripisane osnovne podatke o besedi, kamor sodijo besedna vrsta, vse pregibne oblike (sklanjanje, spreganje, stopnjevanje), slovnične lastnosti, pojavitve, naglasni vzorec, posnetek izgovora (eBralec), samodejno generirani fonetični zapisi (nevronske mreže) in povezave do rabe v korpusu Gigafida 2.0. Vidimo, da je pomnilnik samostalnik moškega spola, neživ, občno ime, z naglasom na prvem i (pomnílnik), pomniti pa nedovršni glagol s povezano iztočnico pomnjenje. Mimogrede, v leksikonu so tudi nestandardne oblike, denimo *pri otrocih ali *neboš, ki so jasno označene. Obstaja že naslednja različica Sloleks 3.0, ki je trenutno na voljo na CLARIN.
V pripravi
Poleg omenjenih virov, ki so izrecno ponujeni na uradni strani viri.cjvt.si/, CJVT na enak način z istim vmesnikom nudi še nekaj drugih orodij in pripomočkov, ki jih najdemo na drugem delu domačih strani na www.cjvt.si/viri-in-orodja/slovarji-in-leksikoni/. Veliki slovensko-madžarski slovar je slovar, ki se precej razlikuje od drugih slovenskih slovarjev. Gesla so izdelali na novo z uporabo računalniških orodij na obsežnem korpusnem gradivu, zaradi česar je v slovarju bistveno več dodatnih informacij. Poleg izgovarjave (eBralec za slovenščino, Profivox HMM TTS tehnološke univerze v Budimpešti za madžarščino) vsebuje še primere uporabe, stalne in nestalne besedne zveze, rabo iztočnic v praksi.
Šolar 3.0 je korpus šolskih izdelkov, torej besedil, ki so jih ustvarili osnovno- in srednješolci v Sloveniji. Ta niso nastale za potrebe projekta, temveč gre za realno rabo v dejanskem okolju. A ključna prednost korpusa v primerjavi z ostalimi izdelki je bogatost spremljajočih informacij. Besedila so opremljena z informacijo o nastanku, letniku oziroma razredu učenca, vrsti šole in besedila ter – najpomembnejše – vključujejo izvirnik in popravljeno različico z učiteljevimi popravki. Izmed dobrih pet tisoč besedil je tako popravljena približno polovica.
Sledilnik 1.0 kaže časovne trende rabe posameznih besedil, kot se pojavljajo v Gigafidi 2.0 in IJS NewsFeedu, ki združuje več kot sto spletnih virov. Ugotovimo lahko, da se beseda pomnilnik prvikrat pojavi leta 1992, največ pa se je uporabljala v letih 2004–2008. Značilne kolokacije so z besedami GB, RAM, 128, 256 in 512. Vse te podatke lahko izluščimo iz Korpusnika, ki išče po petih zbirkah: Standardna slovenščina, Sprotna slovenščina, Akademska slovenščina, Spletna slovenščina in Govorjena slovenščina.
Še eno izjemno orodje je Označevalnik, v katerega skopiramo besedilo (ali naložimo datoteko), nato pa ga razčleni po besedah. Za vsako izpiše obliko, osnovno lemo, besedilno vrsto, oblikoskladenjske lastnosti in še vrsto parametrov, povezanih s položajem in z vlogo v besedilu. Senta je orodje za stavčno poenostavljanje in analizo, STARK je orodje za procesiranje korpusov, torej analizo pojavov v besedilih. Vejice 1.0 postavlja (ali briše) vejice, Svala pa je lokalizacija istoimenskega švedskega orodja za pripravljanje korpusov za usvajanje jezika.
Umetna inteligenca
Pred letom dni se je začel veliki raziskovalni-inovacijski (RRI) program PoVeJMo (Prilagodljiva obdelava naravnega jezika s pomočjo velikih jezikovnih modelov), v okviru katerega razvijajo velike jezikovne modele za slovenski jezik. Jezikovni modeli so široko popularnost doživeli ob predstavitvi ChatGPT novembra 2022, danes pa imajo informacijski velikani skorajda vsak svojega. Medtem ko je OpenAI-jev ChatGPT zaprt in zgolj na voljo za uporabo, Metina Llama pa odprta z javno objavljenimi parametri oziroma utežmi, je poznavanje slovenščine v vseh teh modelih nastalo po naključju. Modeli so prebrskali celoten splet, kot je javno dostopen, in se na tem urili. Na spletu je precej slovenskih vsebin, zato razumejo tudi naš jezik, a so pri tem občutno slabši kot pri interakciji v angleščini. Problemi so tudi v potrebni računski moči in netransparentnosti, zaradi česar je GPT-4 nemogoče prilagoditi za slovenščino, ker si tega ne moremo privoščiti.
Wiki
Nekoliko manj znani del strani CJVT je njihova Wiki platforma, kjer najdemo praktična navodila za uporabo, smernice za sodelovanje, informacije o delovanju, opis podatkovnih zbirk in načinov za samodejni dostop (prek REST API) itd. Kdor želi orodja CJVT resneje uporabiti v svojih izdelkih ali pa zgolj sodelovati, bo odgovore našel na strani wiki.cjvt.si/.
Wiki del strani CJVT.
PoVeJMo bo to spremenil. Infrastrukturo velikih modelov za slovenski jezik nedvomno potrebujemo, a razviti jo bomo morali sami. V tem programu nastaja model SloLLaMa, ki bo prvi odprtodostopen model za slovenščino kot morfološko bogat jezik z malo viri. Korpus za slednje ukazom pa bo osnova za nadaljnje prilagoditve modela za specifično uporabo. Konkretni primeri, ki so del programa PoVeJMo, so predstavitev podatkov v muzejski rabi, prepoznavanje in sinteza govora, uporaba v medicini, generiranje infrastrukturne kode (opis infrastrukture v programski kodi). V programu, ki je financiran iz Načrta za okrevanje in odpornost, sodelujejo tudi Inštitut za novejšo zgodovino, ZRC SAZU in podjetja Semantika, Better, Špica, XLAB, Vitasis.
Gradnja modela bo potekala v več fazah. Naprej bodo zbrali gradiva, jih šifrirali in varno shranili. Besedila bodo nato pretvorili v enotni digitalni format, ki bo strojno berljiv in brez elementov, ki niso primerni za obdelavo. Pred urjenjem modela bodo morali besedila še anonimizirati in psevdonimizirati, torej iz njih odstraniti osebne podatke ter jih nadomestiti z generičnimi nadomestnimi kodami. Nato bosta sledila tokenizacija in urjenej modela, v zadnjem koraku pa bo še obvezno preverjanje kakovosti, kamor sodijo tudi varovalke proti zlonamerni uporabi in preizkušanje učinkovitosti, natančnosti in primernosti.
Ocenjujejo, da za projekt potrebujejo 40 milijard besed, kar je precej več od javno dostopnih besedil v slovenščini na internetu. Projekt ima spletno stran povejmo.si, na kateri lahko oddamo svoja besedila, če imamo zanje ustrezne avtorske pravice. Sproti prikazujejo napredek in do letošnjega septembra so zbrali že 9,2 milijarde besed.
Partnerji CJVT izvajajo več projektov, v okviru katerih nastajajo nova orodja. Poleg PoVeJMo, ki je ta hip največji, je še več manjših. Med njimi je strojno prepoznavanje črkovalnih napak, kar zmore strojni črkovalnik SloNSpell, ki uporablja nevronski model SloBERTa (osnovan na transformerjih). Ta je posebej prilagojen slovenščini in deklasira konkurenčne modele, denimo fastText, ELMo, mBERT, XLM-R, CSE-BERT. SloNSpell je še na preizkušanju, lahko pa si ga ogledamo na repozitorju Hugging Face, kjer so dostopne uteži (huggingface.co/cjvt/SloBERTa-slo-word-spelling-annotator).
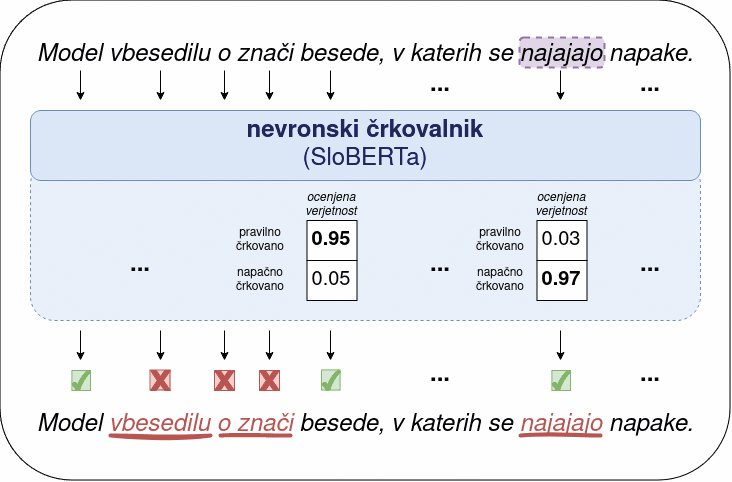
SloNSpell uporablja nevronski model SloBERTa za prepoznavanje napak v črkovanju.
Izgovorov ni več
Dasiravno so računalniki z nami že skoraj stoletje, prva orodja za sobivanje s slovenščino pa segajo v preteklo stoletje, je ključni trenutek napočil zdaj. Končno imamo dovolj zmogljivo strojno opremo, programska orodja (transformerje, velike jezikovne modele), velike zbirke digitaliziranih vsebin in znanje, da lahko slovenščino ukrotimo. Vsi uporabniki jezika imamo na voljo več kot zgolj bergle, v resnici že pravi arzenal orodij za spretno rabo jezika.
Še največji problem je razdrobljenost vseh virov. CJVT ima večino na spletnih straneh, a so nekateri dostopni le z globokimi povezavami – to se bo spremenilo. Drugi nabor orodij, o katerem smo že pisali, je na strani www.slovenscina.eu. Poleg tega pa obstajajo še komercialni igralci, denimo kamniški Amebis ali Alpineon, ki nudijo svoje rešitve in sodelujejo. CJVT-jeva orodja izdatno uporabljajo eBralca, ki je nastal v Amebisu in Alpineonu. Aktivni so tudi na ministrstvih, tudi na področju regulative, s čimer so letos dosegli prevod Applovega iOS v slovenščino.
Pri vseh teh orodjih manjkata dva ključna koraka. Prvi sta povezovanje in konsolidacija, da bodo vsa orodja res zbrana na enem mestu. Drugi, težje rešljivi problem pa je finančna stabilnost. Projektno financirana orodja imajo po izteku projektov težave, ko presahne financiranje, zato pogosto obtičimo z dobrimi orodji, ki jih nato ob pomanjkanju vzdrževanja začenja najedati zob časa. Sčasoma bo treba nanje začeti gledati kot na infrastrukturo in ne na projekte.