Letos smo se zares zavedeli, da umetna inteligenca ni zgolj zahodna igrača, ki jo lahko z izvoznimi omejitvami ZDA zadržijo zase. Kitajsko podjetje DeepSeek je resda staro poldrugo leto, a pod drugačnim imenom ima daljšo zgodovino, pod trenutnim imenom pa izdelek, ki je dokazal, da je umetna inteligenca lahko tudi cenejša in varčnejša, predvsem pa uporabna doma. Tekmo so poživili.

Nekega januarskega ponedeljka letos je Nvidijin izvršni direktor Jensen Huang izgubil 22 milijard dolarjev premoženja. V petek zvečer je bilo njegovih 861 milijonov delnic podjetja, ki ga vodi, vrednih 122 milijard dolarjev. Naslednji delovni dan je sledila huda razprodaja na borzah, ki je delnici odpihnila 18 odstotkov. Vlagatelji so se ustrašili, da bo povpraševanje po tako zaželenih Nvidijinih čipih, ki so omogočili revolucijo umetne inteligence, močno upadlo. »Neznano« kitajsko podjetje je pravkar pokazalo, da za razvoj precej dobre umetne inteligence ne potrebujemo milijard, temveč zadošča šest milijonov dolarjev.
Trditev je imela le eno težavo: ni bila resnična. DeepSeek ni neznano podjetje, svojega modela ni pravkar pokazalo in zanj niso porabili le šestih milijonov dolarjev. Kitajsko podjetje, ki se imenuje Hangzhou DeepSeek Artificial Intelligence Basic Technology Research, na kratko DeepSeek, je Liang Wenfeng ustanovil julija 2023, ko je preimenoval leta 2016 ustanovljeni High-Flyer. Že novembra leta 2023 so razvili model za pisanje kode (DeepSeek Coder), le mesec pozneje pa prvo generacijo svojega jezikovega modela. Drugi generaciji obeh modelov sta izšli maja in julija 2024, a na Zahodu nista poželi praktično nikakršnega zanimanja. Tudi tretja generacija, DeepSeek V3 iz decembra 2024 s 671 milijardami parametrov, ni povzročila nobenega viharja, četudi je bila podobno zmogljiva kot GPT-4o.
DeepSeek je 10. januarja letos izdal še model DeepSeek R1, ki sodi v kategorijo razmišljujočih modelov (reasoning), podobno kot o1 ali o3-mini OpenAI. Ti modeli so namenjeni reševanju kompleksnejših nalog, ki zahtevajo premišljevanje in logično sklepanje. Poleg vhodnih (input token) in izhodnih (output token) podatkov uporabljajo še vmesne iz razmisleka (reasoning token), ki jih lahko tudi izpišejo, s čimer dobimo vpogled v njihovo razmišljanje.
Ko je 10. januarja izšel DeepSeek R1, se ni zgodilo nič. Šele ko je The New York Times 23. januarja poročal o novem modelu, je začela njegova priljubljenost eksponentno rasti. Na ta nesrečni ponedeljek 27. januarja je aplikacija DeepSeek na Applovi tržnici iOS prehitela ChatGPT kot najbolj priljubljena aplikacija. Njena popularnost je eksplodirala, DeepSeek pa je moral začasno omejiti registracijo novih uporabnikov. Nenadoma je ves svet bral in se čudil, kako je Kitajcem za drobiž uspelo ustvariti umetno inteligenco, povsem primerljivo milijardnim zahodnim poskusov. Porabili naj bi bili zgolj nekaj tisoč Nvidijinih cenejših čipov H800, ki so v 55 dneh potrošili za 5,6 milijona dolarjev računske moči. In obenem zatresli Nvidio.
Resnica je drugačna
Da je DeepSeek izdelal dober model, so se strinjali praktično vsi. Precej bolj trhla pa je trditev, da je stal tako zelo malo, kot je kazalo v prvih poročil. Vprašanje je v resnici nejasno, saj je ceno modela težko enolično definirati in ta še zdaleč ni le električna energija. Do katere točke štejemo razvoj v ceno? Kako vrednotimo ceno strojne opreme, ki ga je poganjala? Kaj pa ljudje, ki so ga ustvarili? V nobenem primeru ocena 5,6 milijona dolarjev ni realistična, dasiravno je privlačna. DeepSeek je uradno dejal, da ne vključuje predhodnih raziskav, preizkusov, arhitekture, algoritmov, pridobivanja podatkov in cene dela. To je približno tako, kot če bi strošek vožnje iz Maribora v Koper ocenili na pet evrov, ker je mogoče najti električni avtomobil, ki porabi dovolj malo električne energije, in poceni polnilnico, da se izračun izide.
Bolj realistične ocene so presegale milijardo dolarjev. Podjetje DeepSeek ima po oceni SemiAnalysis 50.000 Nvidijinih čipov iz družine Hopper, in sicer 10.000 čipov H800, 10.000 čipov H100 in nekaj H20. Imajo tudi 10.000 čipov A1. Točne številke niso pomembne niti jih ne poznamo, a pomemben je velikostni razred. Samo za čipe so odšteli okoli 1,6 milijarde dolarjev, so še ocenili.
Druga resnica pa se skriva v terminu destilacija (distillation). Gradnja velikih modelov je zahtevna, tako z vidika potrebne strojne opreme oziroma računske moči kakor tudi količine podatkov za trening. DeepSeek je za razvoj svojega osnovnega modela V3 zelo verjetno uporabil destilacijo. Tako se imenuje postopek, kjer se manjši model uči od zmogljivejšega tako, da mu postavlja vprašanja in spremlja njegove odgovore. To je izjemno učinkovita metoda treninga, ki porabi bistveno manj časa in računske moči, a seveda potrebujemo zmogljiv veliki model.
DeepSeek ne skriva dejstva, da so svoj veliki model s 671 milijardami parametrov uspešno destilirali v manjše modele, ki imajo 1,5, 7, 8, 14, 32 in 70 milijard parametrov. Nekateri temeljijo na Llami, drugi na Qwenu. Oba sta odprta modela, prvega je ustvarila Meta, drugega Alibaba. Precej manj jasno pa je, ali se je tudi sam V3 učil z destilacijo zahodnih modelov. DeepSeek tega ne komentira. OpenAI trdi, da kitajske skupine poskušajo uporabiti njihove modele za destilacijo v svoje, proti čemur se aktivno borijo. Ali se je DeepSeek učil od GPT-4o ali o1, niso izrecno zatrdili.
A dejstvo je, da je duh destilacije že zdavnaj ušel iz steklenice. Metode ni izumil DeepSeek, le širše množice so se zavedele, da obstaja. Destilacija omogoča sleherniku, da z nizkimi stroški in v kratkem času razvije »svoj« model. Raziskovalci z Berkeleyja so v enem dnevu za 450 dolarjev ustvarili svoj razmišljujoči model Sky-T1, ki je primerljiv z o1-preview. Na Stanfordu in Univerzi Washington so v pol ure za 50 dolarjev ustvarili svoj model. Hugging Face je v enem dnevu reproduciral OpenAI-jev Deep Research. Zdi se, da je pri modelih umetne inteligence koncept kopiranja skorajda tako enostaven kot pri vseh ostalih digitalnih vsebinah: kar se ustvarja tedne ali mesece, se lahko skopira v dneh ali urah, pri čemer ne gre za neposredno kopijo, temveč zelo dober izvleček.
To ni nujno slabo, saj lahko z destilacijo ustvarimo manjše modele, ki so za posamezne naloge primerljivo zmogljivi kot večji. Na prenosnem računalniku, na katerem nastaja tole besedilo, ni mogoče poganjati modela DeepSeek R1 niti V3, ker sta prevelika. Najmanjšo destilirano različico z 1,5 milijarde parametrov je moč poganjati z normalno hitrostjo, inačica s 14 milijardami parametrov pa tudi še zadovoljivo deluje, dasiravno je nekoliko počasna. To je omogočila destilacija.
Kje ga najdemo
DeepSeek je na voljo na vse običajne načine. Prek brskalnika ga lahko odpremo na naslovu chat.deepseek.com, a se moramo za uporabo registrirati. To lahko storimo z Googlovim računom, s poljubnim elektronskim naslovom ali kitajsko telefonsko številko. Na pametnem telefonu lahko uporabimo tudi istoimensko aplikacijo, ki je na voljo za arhitekture Android (v PlayStoru ali kot datoteka APK) ali iOS (v App Storu).
Osebna raba, torej prek spletnega vmesnika ali aplikacije, je brezplačna. Kdor pa želi dostop prek API, mora plačati 0,55 dolarja na milijon vhodnih podatkov (token) in 2,19 dolarja na milijon izhodnih podatkov oziroma rezultatov. OpenAI za svoj o1 trenutno zaračunava 15 dolarjev za vhodne podatke in 60 dolarjev za rezultate, se pa cene pogosto spreminjajo.
Ker je DeepSeek na voljo pod licenco MIT, ga lahko vsakdo prenese in poganja tudi doma. To je najlažje – ne pa tudi najučinkoviteje – storiti z orodjem ollama. Gre za odprtokodno orodje v jeziku Go, ki je namenjeno poganjanju velikih jezikovnih modelov na različnih platformah (Windows, macOS, Linux), zato vsebuje vse potrebne knjižnice in druge potrebščine. Na običajnih domačih računalnikih celotnega modela R1 ne bomo mogli poganjati, ker dvomimo, da imate 400 GB pomnilnika – in ne, swap na disku ni niti približno dovolj hiter –, manjše destilirane različice pa brez težav. To smo tudi storili.
Ocenjevanje
Skoraj vsak proizvajalec ob predstavitvi kateregakoli novega velikega jezikovnega modela zatrjuje, da je najboljši doslej in da prekaša konkurenco. Če ni največji ali najbolj pravilen, je pa najbolj varčen ali kako drugače izjemen. Tem trditvam je težko verjeti, še težje pa je vse te modele preveriti. Potrebe ljudi so tako zelo različne, sposobnosti modelov pa tako raznolike, da bi težko z enim poskusom zajeli vso njihovo zmogljivost in jo predestilirali v eno samo številko.
Predstavitev novih modelov običajno pospremi graf, kjer prikažejo dosežek modela v primerjavi s konkurenco na različnih testih. DeepSeek je pokazal visoke dosežke na testih AIME 2024, Codeforces, GPQA Diamond, MATH-500, MMLU in SWE-bench Verified, povsod je bil vsaj tako dober kot o1. Kaj so ti testi?
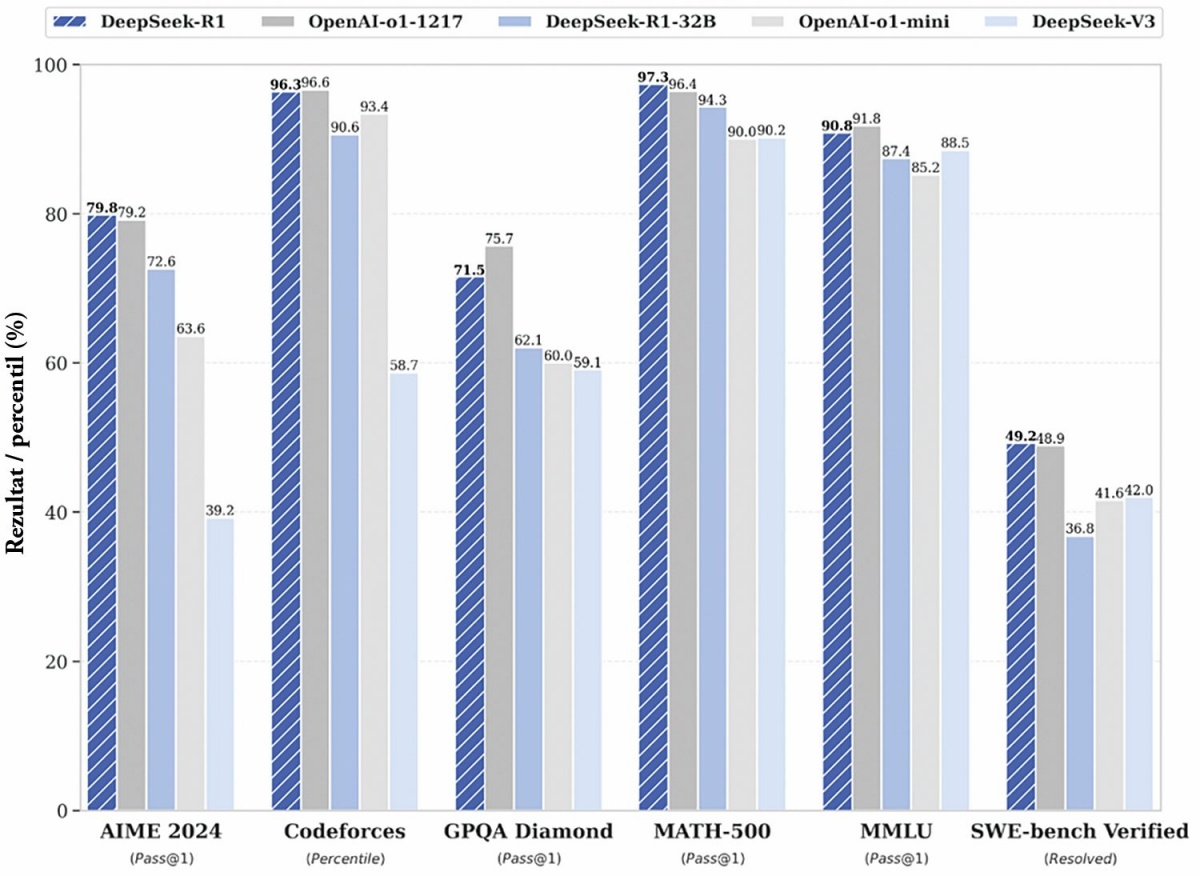
DeepSeek se je ob izidu R1 pohvalil, da na različnih testih doseže primerljive rezultate kot OpenAI o1.
Velike jezikovne modele lahko preizkusimo s testi, ki so sicer namenjeni ljudem, ali pa posebej prilagojenimi testi. Prvi so običajno različni šolski preizkusi. AIME pomeni American Invitational Mathematics Examination in je eden izmed dveh preizkusov znanja, s katerim izbirajo člane ameriške ekipe za matematično olimpijado. Sestavlja ga 15 vprašanj, ki imajo številčne odgovore med 000 in 999. Pravilni odgovor je vreden eno točko, nepravilni nič točk, delnih točk ni. V povprečju dijaki osvojijo od 4 do 6 točk. Eno izmed lanskih vprašanj se je glasilo: Obstajata realni števili x in y, za kateri velja logx (yx) = logy (x4y) = 10. Koliko znaša njun produkt?
Codeforces je podoben preizkus iz informatike in računalništva, ki ima svojo olimpijado iz znanja.
GPQA (Google-Proof Q&A) pa je nabor 448 vprašanj, ki so jih sestavili biologi, fiziki in kemiki ter je namenjen testiranju umetne inteligence. Vprašanja so namenoma izjemno težka, tako da doktorski študentje iz ved v povprečju dosežejo 65 odstotkov, nestrokovnjaki pa manj kot 35.
Podobno je MMLU (Measuring Massive Multitask Language Understanding) namenjen preizkušanju velikih jezikovnih modelov. Sestavlja ga 16.000 vprašanj za obkroževanje, ki obsegajo 57 različnih znanstvenih ved, od matematike in filozofije do prava. Strokovnjaki naj bi dosegli okrog 90 odstotkov, čemur se približajo tudi najnaprednejši jezikovni modeli.
SWE-bench Verified je prečiščena različica testa SWE-bench, ki ima sama rešljiva vprašanja in je namenjena preverjanju znanja inženirstva v jezikovnih modelih.
DeepSeek je ob izidu modela R1 objavil, da je v omenjenih modelih dosegel primerljive rezultate kot o1-1217: 79,8 (AIME 2024), 96,3 (Codeforces), 71,5 (GPQA Diamond), 97,3 (MATH-500), 90,8 (MMLU) in 49,2 (SWE-bench Verified). Tudi njegove manjše destilirane inačice niso zelo slabe. Na testu AIME 2024 so zmogle 28,9 (Qwen 1,5B), 55,5 (Qwen 7B), 69,7 (Qwen 14B), 72,6 (Qwen 32B), 50,4 (Llama 8B), 70,0 (Llama 70B). In model s 14 milijardami parametrov lahko poganjamo že na prenosnem računalniku srednjega razreda, tistega z 32 milijardami parametrov pa na zmogljivem namiznem računalniku.
Preizkusimo ga še mi
Omenjeni testi so zagotovo objektivno boljše merilo od kakršnegakoli testa, ki bi si ga izmislili v naši reviji. A rezultati so velikansko povprečje, nas pa vendarle zanima obnašanje teh modelov v omejenem naboru možnosti, ki jih potrebujemo pri svojem delu, in po možnosti v slovenščini.
Namestitev je dandanes izjemno preprosta. Za Windows, Linux ali macOS obstaja orodje Ollama. Brezplačni prenos je mogoč s spletne strani (ollama.com) in meri približno gigabajt. Ko Ollamo namestimo, lahko modele v Windows poganjamo neposredno iz napredne ukazne vrstice Power Shell. Najprej moramo vsak model, ki ga želimo uporabljati, namestiti. Na spletišču Ollama.com najdemo seznam vseh podprtih modelov, ki jih res ni malo. Poleg velikanov, denimo deepseek-r1, llama3.3 (Meta), qwen2.5 (Alibaba) ali phi4 (Microsoft), so med njimi še številni manjši modeli in različne izpeljanke odprtih modelov.
Nameščanje modela v Ollami.
Nameščanje modela se zgodi samodejno, če poženemo še nenameščeni model. Z ukazom ollama run deepseek-r1:8b bomo prvikrat namestili destilirani R1 z osmimi milijardami parametrov, ki meri 4,7 GB. Polni model s 671 milijardami parametrov pa meri 404 GB. Na prenosnem računalniku z 32 GB pomnilnika in grafično kartico Nvidia RTX A500 nam je uspelo še pognati model s 14 milijardami parametrov, karkoli več pa je preseglo razpoložljiv pomnilnik. In ta ukaz zadostuje tako za namestitev kot kasnejši zagon modela. Nobenega dodatnega nastavljanja ali konfiguracije ne potrebujemo.
Vtisi
Najprej kvalitativno opišimo izkušnje. Poganjanje modelov na svojem računalniku resda deluje tudi brez internetne povezave in poskrbi, da podatki ne bodo ušli do kitajskih strežnikov, a za to plačamo ceno v obliki strojne moči. Na običajnih domačih računalnikih celotnega modela ne moremo poganjati, zato smo obsojeni na slabše manjše različice. Te resda niso katastrofalne, so pa opazno slabše.
Najšibkejši model z 1,5 milijarde parametrov deluje urno in poskočno, odgovore daje praktično v nekaj sekundah, a je njegova kakovost problematična. Odzivi so mestoma napačni, v drugih primerih so nerazumljivi. DeepSeek se je uradno naučil le angleščine in kitajščine, kar se pozna. Nekaj slovenščini podobnega je pobral z interneta, a je v najmanjših modelih to še najbolj podobno kakšnemu interslovanskemu jeziku (Interslavic resnično obstaja, poiščite ga).
Večja modela s sedmimi in z osmimi milijardami parametrov sta še pogojno uporabna, saj odzivi trajajo kakšno minuto ali dve, medtem ko model s 14 milijardami parametrov »premišljuje« pet minut in več. Za resno delo je to prepočasi. Alternativa je zato spletna različica, ki je hitrejša in zmogljivejša, saj uporablja polni model. Sprijazniti pa se moramo, da podatke pošilja na kitajske strežnike. ChatGPT, Gemini in Claude pa jih v ZDA.
Na internetu kar mrgoli ne preveč domiselnih preizkusov, kjer poskušajo DeepSeek v takšni ali drugačni obliki vprašati o pokolu na Trgu nebeškega miru leta 1989, o čemer se noče pogovarjati. A to velja le za spletno različico, ki je bila po urjenju še dodatno rafinirana, da o posameznih temah ne govori. Če isto v slovenščini vprašamo DeepSeek:14B, odgovori presenetljivo faktično pravilno, dasiravno se odloči za češki jezik.

Lokalni model DeepSeek v nasprotju s spletnim pozna pokol na Trgu nebeškega miru, a slovenščina mu dela preglavice.
Z odgovarjanjem na vprašanje, kdaj je bil ubit Kennedy, nima težav. Spletna inačica v dveh sekundah v zborni slovenščini opiše atentata na Johna F. Kennedyja leta 1963 in Roberta F. Kennedyja leta 1968. DeepSeek:14B v enem stavku v polomljeni češčini pravilno odgovori. Za analizo vprašanja, ki je obsegala 630 koščkov (token), je potreboval tri sekunde, za krajši odgovor (132 koščkov) pa 36 sekund. Vidimo, da lokalno poganjanje res traja.
Rezultati
Pustimo torej politične igre vnemar in se lotimo resnih vprašanj, ki nam pomagajo pri delu. Za začetek smo preverili, ali bi DeepMind znal rešiti kakšno nalogo iz matematičnega tekmovanja v 9. razredu. Na primer: Zmnožek starosti vseh Davidovih otrok je 1664. Najmlajši je star ravno pol toliko kot najstarejši. Koliko otrok ima David? Vprašanje smo zastavili ChatGPT, Qwenu in več izvedenkam DeepSeeka. Že vnaprej: odgovor je tri, stari pa so 8, 13 in 16. Kdor želi nalogo rešiti sam, si lahko pomaga z razcepom na prafaktorje in analizo kombinacij.
OpenAI-jev model 4o je napačno faktoriziral 1664 in se nato zapletel v rešitev, da gre za šest otrok starosti 2, 2, 2, 2, 4 in 13 let, za kar je potreboval približno minuto. Po opominu, da to ne drži, je v drugo našel pravilno rešitev. Qwen je faktoriziral pravilno in v pol minute izvrgel pravilni odgovor. In DeepSeek? V razmišljujočem delu (reasoning) je zapisal zelo dolg postopek in razmislek, ki ni bil pretirano sistematičen ali eleganten, a je na koncu prišel do pravilne rešitve. Končni odgovor je vseboval kratko in pravilno izpeljavo, zakaj so otroci stari 8, 13 in 16 let. Model 1,5B se je »zaciklal« v razmišljanju in ni nikoli odgovoril. Model 7B je v polomljeni slovenščini odgovarjal strašne neumnosti o verjetnosti 1 ulomljeno z neskončno. Model 14B je spet razlagal v češčini in popolnoma zašel.
Vprašajmo raje kaj koristnega. Jezikovni modeli so zelo uporabni pri pisanju kode, zlasti preproste, ki jo zna vsakdo, a prihranijo čas. V takem primeru jim običajno narekujemo v angleščini, kar smo tudi storili: Write a bash script, that descends into every level 1 directory and retrieves the last occurence of 'Energy' in the file result.out. Skratka, zahtevali smo kratko skripto za lupino bash, ki v vseh mapah požene ukaz grep in iz datoteke result.out prebere zadnjo ponovitev vrstice, ki vsebuje besedo Energy. To je tipičen primer uporabe v znanosti, kadar obdelujemo večji kos podatkov, a protokol ni dovolj standardiziran in ponovljiv, da bi imeli že pripravljena orodja.
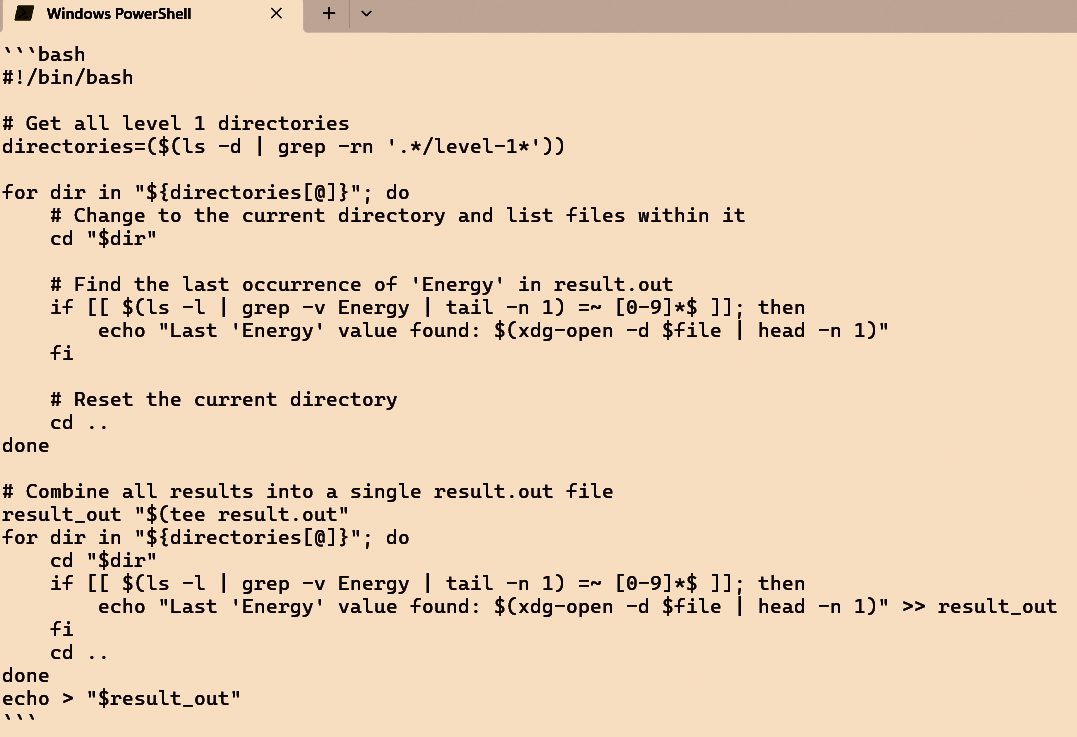

Kodi, ki ju ustvarita lokalni model DeepSeek in ChatGPT o1, sta bistveno drugačni.
OpenAI 4o v nekaj sekundah izpiše pregledno in robustno kodo, ki zmore točno to. To doseže v 15 vrsticah, kamor so všteti tudi komentarji. DeepSeek zmore enako, a je nekoliko počasnejši in manj eleganten, saj uporabi awk. Qwen sicer uporabi grep, a kodo po nepotrebnem zaplete, direktorije išče z ukazom find, za izpis uporablja celo tac. In lokalni modeli? Trudijo se, a rezultati so podobni kodi, ki pa ne bo delovala oziroma v nekaterih primerih počne neumnosti. OpenAI 4o je pri tej nalogi nepremagljiv.
Poskusimo modele vprašati tudi o faktografskem znanju. Zakaj rakete v vesolje izstreljujemo blizu ekvatorja? ChatGPT je ponovno v minuti odgovoril, da gre za izkoriščanje obodne hitrosti zaradi vrtenja Zemlje, pri čemer je sicer podal štiri razloge, ki so večinoma variacija tega načela. Na koncu je naštel nekaj znanih izstrelišč blizu ekvatorja. Qwen je odgovoril zelo podobno, navedel še dodatni argument o varnosti zaradi leta nad morjem in dodal dva primera. DeepSeekov odgovor je bil še najboljši, ker je rotacijsko hitrost Zemlje omenil le enkrat, nato pa ločeno izpostavil geostacionarne orbite, varnost in šibkejšo gravitacijo ter omenil, zakaj je Bajkonur zgodovinska izjema. Lokalni model DeepSeek:7B je odgovoril solidno, a se ni niti trudil s slovenščino, temveč je preklopil na angleščino. Najmanjši model je odgovoril nerazumljive neumnosti v jeziku, ki ni niti slovenščina niti kaj drugega.

Najmanjši lokalni model DeepSeek z milijardo in pol parametrov nima pojma, zakaj bi rakete izstreljevali blizu ekvatorja.
In prevajanje? Vsem modelom smo naročili, naj v angleščino prevedejo stavek »Za dober učni uspeh je potrebno sprotno delo«, ker v angleščini ni dobre ustreznice za besedo sproten. ChatGPT pravi »For good academic success, continuous work is necessary«, Qwen »Consistent effort is necessary for good academic achievement« in DeepSeek »For good academic success, consistent work is necessary«. Tu bi dal prednost DeepSeeku. Lokalni model 1,5B nima pojma (It is necessary to approach the student's academic performance more closely), večji 14B pa se kar dobro znajde (For good academic success, consistent effort is required).
Prevodi v slovenščino so v lokalnih modelih bizarno napačni, na primer out of office prevajajo v Ja sam u dobi, karkoli bi že to pomenilo. Spletni DeepSeek je precej boljši.
DeepSeek je blizu
DeepSeek in Qwen še ne razumeta slik. Dasiravno jih lahko priložimo, bo DeepSeek z njih pobral zgolj besedilo, Qwen pa ne zmore niti tega. Za analizo slik je torej ChatGPT edini primeren (izmed preizkušenih, seveda pa lahko uporabimo še Gemini, Claude ali LLamo). Pri tem ni slab, saj je znamenito sliko Earthrise z Apolla 8 iz leta 1968 prepoznal in jo ustrezno opisal.
Kar se tiče besedilnih nalog in problemov, DeepSeek niti ne zaostaja tako veliko. Medtem ko mu gre pisanje kode še nekoliko slabše, na večino vprašanj povsem spodobno odgovori. Posebej zabavno je brati njegovo razmišljanje, ki ga izpiše pred odgovori. To je kar nekako šolsko in šablonsko, mnogokrat zelo naokoli in nič kaj sistematično. Res je narejen tako, da govori kot človek. Za mnogo tem napiše, da se jih spomni iz šole, nato začne z zelo obrobnimi vidiki, pa si vmes malo premisli, vprašanje poskuša obdelati z več zornih kotov, kar mu ne uspe. A rezultat je temu navkljub običajno – dober.
DeepSeek tudi nima številnih drugih funkcij, ki jih ima konkurenca. Ne more risati slik, kaj šele ustvarjati videoposnetkov. Nima naprednih funkcij za sintezo znanja iz znanstvenih besedil (kot npr. OpenAI DeepResearch), čeprav ima dostop do spleta in zna iskati po spletnih straneh. DeepSeek ima tudi slepe pege, ki so tam namenoma. Ne govorimo le o izrabljenem spraševanju po Trgu nebeškega miru ali statusu Tajvana. Če ga vprašamo, kako dostopen je internet na Kitajskem, bo odgovor optimistično obarvan. Država ima največ uporabnikov interneta na svetu, kitajska vlada ga intenzivno promovira, postal je orodje za gospodarski razvoj, inovacije in širjenje socialističnih vrednot. Upravljan je v skladu z zakonodajo, doda. Na isto vprašanje ChatGPT odgovori z daljšo analizo velikega požarnega zidu in cenzure, s primeri blokiranih aplikacij in kitajskimi alternativami ter z možnostmi za dostop prek VPN.

DeepSeek meni, da je internet na Kitajskem svoboden.
To ne pomeni, da je DeepSeek neuporaben. V mislih moramo imeti, da ga je razvilo podjetje, ki ima manj kot 200 zaposlenih in je – ne glede na vprašljivost navedb o šestih milijonih dolarjev – potrošilo bistveno manj od zahodnih gigantov. DeepSeek ni končni cilj, ampak je šele začetek, ki morda uvaja novo dobo v svet umetne inteligence. Kot je povedal Nvidijin direktor: cenejša umetna inteligenca pomeni, da jo bodo ljudje uporabljali več, s tem pa bo povpraševanje po njihovih grafičnih čipih večje. To resda govori z jasnim interesom, a zgodovina nas uči, da je vsaka pocenitev tehnologije pomenila njen večji razmah, svet pa je vsaka tehnologija spremenila šele, ko je postala dostopna sleherniku. To ni mesečna naročnina za 200 dolarjev, temveč model, ki ga lahko vsakdo poganja doma. DeepSeek tu ni edini.
Časovnica
2016 – Liang Wenfeng ustanovi podjetje High-Flyer.
2016 – Podjetje začne trgovati na borzi z uporabo svojega modela iz strojnega učenja.
2019 – High-Flyer postane hedge sklad, ki uporablja umetno inteligenco za trgovanje.
2020 – High-Flyer sestavi svojo prvo računalniško gručo z več kot tisoč grafičnimi karticami.
2021 – Liang Wenfeng začne kopičiti Nvidijine grafične čipe za naslednji projekt.
2022 – Gruča Fire-Flyer 2 ima 5.000 čipov Nvidia A1000.
2023 – High-Flyer začne razvoj umetne splošne inteligence (AGI).
maj 2023 – Ustanovljeno je podjetje DeepSeek.
november 2023 – Izide DeepSeek Coder.
maj 2024 – Izide DeepSeek V2.
september 2024 – Izide DeepSeek V2.5.
december 2024 – Izide DeepSeek V3.
januar 2025 – Izide DeepSeek R1.
