Preizkusili smo novo orodje za generativno ustvarjanje videoposnetkov z umetno inteligenco, ki ga je izdal OpenAI. Po velikem uspehu ChatGPT in pred tem DALL-E so bila pričakovanja do Sore velika. V veliki meri jih je izpolnila, a kot ostala orodja tudi ta zahteva dobršno mero znanja in prakse.
Slika pove več kot tisoč besed, videoposnetki pa jih vsebujejo 24 ali 25 na sekundo. Rečenica velja tudi v obratni smeri, saj je ustvarjanje videoposnetkov z umetno inteligenco bistveno težje in potratnejše od izpisa besedila in tudi posameznih slik. A to ni ustavilo razvijalcev, ki generirane videovsebine vidijo kot naslednji logični korak, zdaj ko je ustvarjanje slik že zelo dobro (a še daleč od popolnega).
OpenAI je lanskega decembra izdal model Sora, ki je ime dobil po japonskem izrazu za nebo, s čimer izraža zamisel o neomejenem potencialu za ustvarjalnost, sta dejala Tim Brooks in Bill Peebles, ki vodita razvoj. Na Soro smo morali v resnici kar dolgo čakati, saj je OpenAI že februarja lani pokazal delujoč model, ki pa so ga odprli le zelo omejeni skupini raziskovalcev. Decembra so naposled ocenili, da so ga naučili dovolj spodobnosti, da ga lahko spustijo v širni svet naročnikov. Za uporabo modela, ki ga imenujejo Sora Turbo, saj je tudi hitrejši oziroma manj potraten, potrebujemo naročnino na ChatGPT Pro ali ChatGPT Plus.
Paketi
Sora je na voljo naročnikom paketov Plus, Team ali Pro. Za zdaj uporabniki brezplačne različice ali paketov Enterprise in Edu nimajo dostopa do nje.
ChatGPT Plus ali Team ChatGPT Pro:
- neomejeno število slik in videoposnetkov
- ločljivost 720p
- dolžina 10 sekund
- dva videoposnetka sočasno
- vodni žig na videoposnetkih neomejeno število slik in videoposnetkov
- ločljivost 1080p
- dolžina 20 sekund
- pet videoposnetkov sočasno
- prioriteta pri ustvarjanju
- videoposnetki brez vodnega žiga
- Cena: 20 dolarjev mesečno Cena: 200 dolarjev mesečno
Zadnjo v našem uredništvu imamo, zato smo se lahko ves vikend igrali s Soro. Najcenejši paket pomeni, da smo pri uporabi nekoliko omejeni. Število slik ali videoposnetkov, ki jih ustvarimo, resda ni omejeno, a naenkrat lahko generiramo samo eno. To je precej večja omejitev, kot bi si mislili, ker so čakalne dobe (queue) znatne. Ko se prvikrat lotimo ustvarjanja, se video ustvari v nekaj deset sekundah, a z intenzivno rabo nas Sora pomika čedalje nižje po lestvici prioritete, zato lahko na posamezno sekvenco čakamo tudi deset minut in več. Ker je prvi rezultat redkokdaj že dovolj dober, to v praksi pomeni, da se bomo načakali. Vsaka iteracija bo trajala nekaj minut, četudi želimo popraviti le malenkost. To velja imeti v mislih, preden se lotimo ustvarjanja s Soro.
Prvi koraki
Soro najdemo na predvidljivem naslovu sora.com, kjer se prijavimo z enakim uporabniškim imenom in geslom kakor v ChatGPT. OpenAI uradno ne dovoli deljenja gesel in to z zmerno strogostjo tudi uveljavlja. Prijava od doma s službenim računom ni delovala, dokler nismo vnesli dodatne kode, ki jo pošlje po elektronski pošti. Zanimivo je, da je Sora očitno pozorna na naslov IP, saj je ne moti drugi računalnik na istem omrežju, medtem ko isti računalnik na drugem naslovu pač. Uradnih pojasnil iz OpenAI seveda ni, razen že omenjenih pogojev uporabe, ki prepovedujejo deljenje gesel.
Uporaba Sore je precej intuitivna, dosti bolj od Midjourneyja, ki je zahteval prijavo v Discord in potem uporabo ustreznih stikal ter ključnih besed, rezultati pa so se izrisovali v neskončnem pogovoru vsem na vpogled. Sora sledi klasični paradigmi, ki vsebuje prijavo z uporabniškim imenom in geslom na spletni strani. Ta je potem minimalistično oblikovana. Na levi strani so bližnjice do podstrani Explore, Images, Videos, Top, Likes in do knjižnic My media, Favorites, Uploads in Trash. Ustvarimo lahko tudi svoje podmape, če želimo delo oziroma izdelke primerno organizirati.
Zgoraj desno so, kot smo navajeni, nastavitve. Spremenimo lahko filtre za izpis vsebin, postavitev, pogledamo čakalno vrsto in splošne nastavitve profila. Najpomembnejši del pa se skriva po celotni spodnji širini zaslona, kamor vpišemo poziv (prompt) za generiranje slik ali videoposnetkov in izberemo osnovne parametre, kot so trajanje, ločljivost, filter. Sora, dasiravno oglaševana kot orodje za izdelavo videoposnetkov, zmore ustvarjati tudi posamezne slike, ne le videoposnetkov. Preden se lotimo svojih stvaritev, se je koristno sprehoditi po že izdelanih (Images, Videos ali Top), da dobimo občutek, kaj je mogoče. Ob izdelkih drugih avtorjev si lahko ogledamo tudi pozive, ki so do njih vodili. Če se želimo lotiti poganjanja brez kakršnegakoli branja navodil ali ogleda video priročnikov (tutorials), je to koristen »šnelkurs«. V vsakem primeru tvegamo, da bomo brez uka in truda ostali na ravni osnovnošolske rabe Worda, torej izkoriščanju desetine funkcionalnosti ali pa še to ne.
Začetna stran Sore
V praksi
Najprej poudarimo očitno. Sora je računsko zahtevna, zato je lokalno ne moremo poganjati. Tudi na strežnikih OpenAI ni neomejeno prostora, zato moramo na proste cikle čakati. S cenejšim naročniškim paketom Plus smo lahko ustvarjali le en posnetek hkrati, pa še na tega je bilo treba počakati. Strežniki so zasedeni, zato smo v povprečju čakali nekaj minut, četudi OpenAI obljublja enominutni zamik. V praksi se je izkazalo, da je intenzivna uporaba v kratkem obdobju podaljšala čakalno dobo, tako da smo morali na koncu na štiri posnetke čakati tudi pol ure (Sora omogoča ustvarjanje ene različice posnetka, dveh ali štirih z istim pozivom).
Razvoj modelov za ustvarjanje slik in videoposnetkov
Prva generacija: generativna kontradiktorna omrežja (GAN) 2014–2021 Izumljena leta 2014.
Ustvarjanje deepfakov.
Urijo tako, da dve omrežji tekmujeta.
Ustvarjajo dobre slike.
Težaven trening, malo nadzora, neprimerna za praktično uporabo.
Druga generacija: difuzijski modeli za slike 2021–2023 Poganjajo DALL-E, Stable Diffusion in Midjourney.
Sliko ustvarijo z iterativnim difuzijskim procesom.
Enostavnejši za urjenje, enostavna uporaba, zanesljivo delovanje.
Bistveno boljše slike od modelov GAN.
Tretja generacija: difuzijski modeli za video 2023– Iterativno ustvarjajo videoposnetke iz besedilnih pozivov.
Uporabljajo transformerje.
Videoposnetki so visoke kakovosti.
Izjemno drago urjenje.
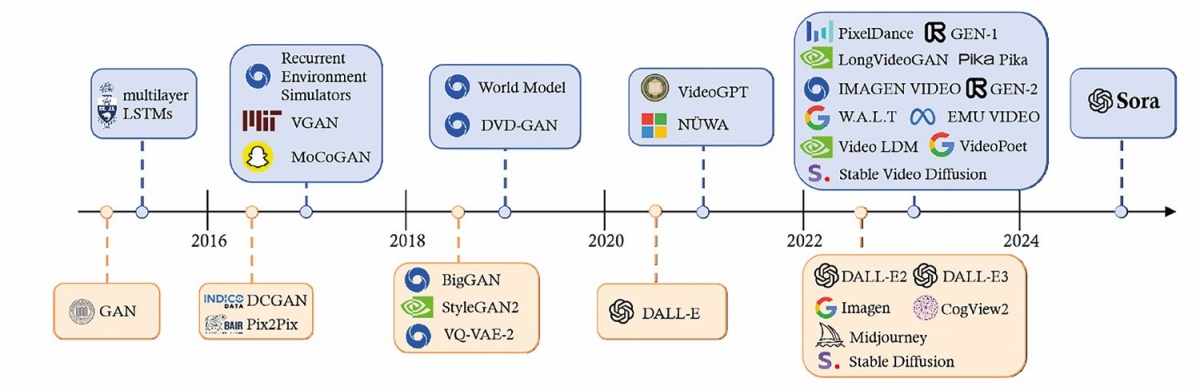
Časovnica razvoja modelov za ustvarjanje slik in videoposnetkov (Yixin Liu et al. Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models, 2024)
Zanimivo je bilo spremljati, kako dobro razume opise in kje se ji zatakne. Pri krajših pozivih težav običajno nima, imamo pa tedaj seveda manj nadzora nad končnim izdelkom. Če je opis daljši, nekajvrstični, je lahko rezultat zelo dober ali pa zelo slab. Zmede se na nepredvidljivih mestih. Medtem ko je poziv Donald Trump narisal zelo podobno osebno ameriškemu predsedniku, je opis American president Donald Trump izrisal povsem neznano osebo. Izkaže se, da je treba pri daljših opisih primerno strukturirati pozive, in sicer od bolj pomembnih informacij za kader do manj pomembnih, na koncu pa lahko podamo še vizualna in slogovna navodila. Tega se najhitreje naučimo iz primerov, ki so jih izdelali drugi ljudje, in prakse.
V nekaterih primerih je bilo šepanje modela povsem nerazumljivo. Preprostega posnetka psa, ki bi na dvorišču hiše ob gozdu odgnal medveda, Sora ni in ni mogla ustvariti. V vseh poskusih sta se borila dva psa. To seveda ne pomeni, da Sora tega ni sposobna, a če povprečno sposobnemu avtorju teh vrstic v eni uri ni uspelo ustvariti takšnega prizora, potem model še ni primeren za najširšo rabo. S čimer ni nič narobe.

Sora ni znala ustvariti posnetka psa, ki bi odgnal medveda, ni pa imela težav s posnetkom, kjer medved napade psa.
Sora ima tudi omejitve, česa ne sme ustvariti. Nasilje, pornografija in objektivno žaljive vsebine so prepovedani, Sora se bo jasno pritožila nad neskladjem s pravili. A včasih je tudi muhasta. Posnetek ameriškega predsednika, ki sedi na železnem prestolu iz Igre prestolov pred klečečimi ljudmi, je bil povsem dopusten, enak poziv, kjer namesto ljudje piše Kitajci, pa je sprožil varnostni mehanizem in se ni izrisal.

Enovrstični poziv je narisal prepričljiv prizor.
Napredne možnosti
Poleg besedilnih opisov lahko kot poziv uporabimo tudi slike ali videoposnetke. Dopišemo jim lahko tudi opis, kaj bi želeli popraviti. Sora lahko slike predela v videoposnetke. Če ne dopišemo nobenega besedila, bo poskusila uganiti, kaj se je najverjetneje zgodilo. Če je na sliki pes, bo ta pomahal z repom in privzdignil ušesa, če pa je slika slapu, bo voda tekla. Kakšnih dramatičnih prizorov ni pričakovati.

Easy smo poravnali njena ušesa.
To se seveda lahko korenito spremeni, če Sori tako zaukažemo. Pes se lahko uleže in zaspi, lahko pa se zgodi tudi potres in se hiša podre. Čim bolj so naše želje oddaljene od slike, tem več možnosti je za artefakte in čudne prizore na končnem posnetku. Najbolj zamudno je predelovanje obstoječih videoposnetkov, ki jih lahko Sora spremeni. Poletni piknik lahko preslikamo v zimsko okolje, vožnjo avtomobila po podeželski cesti lahko spremenimo v dirko po futurističnem japonskem mestu, v panoramo Dubrovnika lahko dodamo vesoljce in še kaj. Sora omogoča predelavo videoposnetkov po besedilnem opisu, lahko pa naložimo tudi dva videoposnetka, da ju nekako združi, vsebine prvega vgradi v drugega ali obratno. Rezultati postanejo z malo vaje resnično prepričljivi.
Drugo zelo pomembno vprašanje je, kako dobro Sora pozna resničnost. Tu ne mislimo na fiziko in stvarnost, temveč na dejanske kraje, dogodke in ljudi. Z drugimi besedami: ali je Sora uporabna le za ustvarjanje generičnih vsebin in predelavo obstoječih ali pa omogoča tudi ustvarjanje konkretnih vsebin, ki spominjajo na realnost. Ameriškega predsednika pozna, središče Ljubljane tudi, Blejski otok ji ne dela težav, Celja pa že ne pozna več na pamet. To pomeni, da se je Sora učila na realističnih posnetkih, ki so bili primerno označeni, in da se jih je tudi naučila. Vsaj nekatere.

Takole si Sora predstavlja vesoljski krožnik, ki pristane v stari Ljubljani. Ljubljano je narisala samo iz opisa brez slike.

Celja Sora ne pozna.
Zgodboris
Nekoč davno smo pisali o ustvarjanju risank (Kako nastane risanka, Monitor 06/14). Tedaj smo se naučili, da je snemalna knjiga ali zgodboris (storyboard) prva vizualna podoba, ki nastane v postopku ustvarjanja risanke ali filma. To funkcionalnost ima tudi Sora in omogoča natančen nadzor nad izdelkom.
S klikom na gumb Storyboard se pokaže urejevalnik videoposnetka, v katerem lahko urejamo opise. Če smo začeli iz slike, je prvi opis naredila že Sora, če pa ustvarjamo iz besedila, ga moramo napisati sami. Nato lahko dodamo dodatne opise, kaj naj se zgodi v posameznem trenutku. S tem lahko zelo natančno režiramo posnetek, saj vplivamo tako na dogajanje kakor na posnetek. Psu lahko naročimo, da zalaja, posnetek pa oddaljimo ali približamo, zavrtimo, premaknemo itd. Zgodboris je izjemno zmogljiva metoda, ki je v resnici ključna, če želimo iz Sore iztisniti največ. Vse ostale so zgolj ogrevanje.
Od sovražnika do pomočnika
Regulacija rabe umetne inteligence je bila ena izmed ključnih zahtev v treh velikih stavkah, ki so v zadnjih dveh letih potekale v Hollywoodu. Od maja do septembra 2023 so stavkali scenaristi, od julija do novembra 2023 so igralci, od julija 2024 pa poteka stavka glasovnih igralcev in igralcev v videoigrah. V aktualni stavki je regulacija rabe umetne inteligence celo glavna zahteva, v preostalih pa je bila ena izmed pomembnejših.
A kot že ničkolikokrat v zgodovini so stavke zgolj opozorile na problem, pogajanjem pa je uspelo zagotoviti nekaj zaščite, a tehnologije seveda niso mogle odpraviti. Umetna inteligenca je v filmski in igričarski industriji neizbežna, zato so edina smiselna pogajanja o tem, kako jo odgovorno uporabljati.
Pomisleki so večplastni in presegajo zgolj poenostavljene trditve, da bo umetna inteligenca zamenjala igralce, scenariste in druge ustvarjalce. Ko OpenAI, Google in Meta urijo svoje modele, ti preštudirajo vso dostopno vsebino, ki je pogosto tudi avtorsko zaščitena. Samo zato ker je napovednik filma objavljen na založnikovem kanalu na Youtubu, še ni nezaščiten in prosto dostopen za urjenje komercialnih modelov, toda njihovi avtorji počnejo prav to.
A letos je oskarja za najboljšega glavnega igralca prejel Adrian Brod za vlogo v filmu Brutalist. Njegove madžarske vrstice v filmu je umetna inteligenca popravila, da je zadel pristni naglas maternih govorcev. Harrison Ford je v filmu Indiana Jones in artefakt usode v prizorih, ki se dogajajo v preteklosti, pomlajen z umetno inteligenco. Podobno je Tom Hanks v filmu Tukaj precej mlajši na enako umeten način.
Avtorji umetne inteligence so ugotovili, da bo Hollywood prej ali slej sprejel njihova orodja. Da bi se to zgodilo prej in ne slej, pa se trudijo na različne načine. Marca letos je OpenAI v Los Angelesu organiziral festival filma umetne inteligence. Napovedujejo se ogromna vlaganja, denimo Marvel bo v umetno inteligenco vložil 400 milijonov dolarjev. Lionsgate je lani začel sodelovati s podjetjem Runway pri razvoju svojega modela.
Umetna inteligenca zagotovo ne bo nadomestila velikih igralskih in režiserskih imen, ki so bolj blagovna znamka kot delavci, bo pa zagotovo omogočila, da bo produkcija potekala hitreje in ceneje. Namesto stotin statistov jih bodo potrebovali manj, manj scenskih delavcev bo postavljalo manj fizičnih scen, asistent asistenta nekega tehničnega opravila morda ne bo več potreben. Po drugi strani pa bo umetna inteligenca omogočila ustvarjanje velikih filmov tudi posameznikom, ki imajo ideje, pa nimajo velikih proračunov. Kdo ve, morda se v kakšni garaži že kali naslednji Quentin Tarantino, česar v preteklem svetu brez podpore velikih studiev ne bi nikoli izvedeli, umetna inteligenca pa mu bo omogočila lastnoročno izstrelitev v središče Hollywoodu.

Ne glede na izvor posnetka, bodisi iz zgodborisa bodisi zgolj iz opisa ali slike, ga lahko izboljšamo. V ta namen ima Sora funkcije Edit remix, Edit prompt, View story, Re-cut, Remix, Blend in Loop. Te počno točno to, na kar gre sklepati iz poimenovanj. Edit remix, če je bil začetni vir videoposnetek, in Edit prompt, če smo začeli z besedilom, omogočata popravljanje videoposnetka tako, da ga ustvarimo znova z nekoliko spremenjenim pozivom. View Story prikaže zgodboris, ki ga Sora interno vsakokrat ustvari, četudi smo jo uporabili v osnovnem načinu. To že omogoča fini nadzor in spremembe posnetka. Vsakokratni izris, četudi z istim pozivom, daje drugačen rezultat, ker začetni šum ni nikoli enak.
Če želimo spremeniti konkretni izdelek, moramo uporabiti Re-cut ali Remix. Prvi omogoča, da izberemo odlomek iz videoposnetka in ga nadalje obdelujemo, Remix pa spremembe v celotnem videoposnetku. Te so lahko različne intenzitete, od manjših popravkov do korenitega redizajna. A v vseh primerih je začetna informacija obstoječi videoposnetek, zato bo tudi rezultat njemu podoben. Blend omogoča, da vanj vtkemo novi posnetek, Loop pa izdelavo neskončnih videoposnetkov, ki so lepo zlepljeni v ponavljanko.
Na ramenih velikanov
Sora ni nastala v vakuumu niti ni vzklila iz nič, temveč je plod razvoja, ki intenzivno poteka približno desetletje. Leta 2014 je Ian Goodfellow v doktorski disertaciji predstavil koncept GAN (generative adversarial network). Pri tej metodi uporabljamo dve nevronski mreži, ki tekmujeta ena proti drugi pri izboljševanju kakovosti slike. Rezultat tega postopka je izris sintetične slike, ki je nastala v nevronskih mrežah. Goodfellow je kasneje delal v Google Brainu, OpenAI, Applu, trenutno pa je spet v Googlu. Njegov mentor pri doktoratu je bil znameniti kanadski strokovnjak za globoko učenje in nevronske mreže Yoshua Bengio, ki je leta 2018 skupaj z Geoffreyjem Hintonom in Yannom LeCunom prejel prestižno Turingovo nagrado.
Kako stane en videoposnetek
Čeprav je OpenAI sila zadržan o tehničnih podrobnostih Sore, lahko ocenimo računsko zahtevnost in porabo energije iz podatkov za difuzijske transformerje. Desetsekundni posnetek s 24 sličicami na sekundo gradi 240 slik, ki jih Sora preslika iz realnega prostora v latentnega. Predpostavimo 8-kratno kompresijo, kot to velja za difuzijske transformerje iz leta 2023 (članek Scalable Diffusion Models with Transformers), pa imamo okrog 30 slik. Sora ima verjetno okrog 20 milijard parametrov. Iz teh podatkov lahko zelo na grobo ocenimo, da so za trening potrebovali okrog 10^25 FLOP. To je okrog štiri tisoč procesorjev Nvidia H100, ki delujejo mesec dni. To je seveda zgolj golo grajenje modela, medtem ko priprave podatkov nismo upoštevali.
Ta strošek OpenAI plača enkrat. Strošek izrisa pa nastopi ob vsakokratni uporabi. Glede na ločljivost posnetkov in trajanje moremo grobo oceniti, da izris porabi 10^18 FLOP. To pomeni, da ena kartica Nvidia H100 v uri izriše nekaj minut posnetka. Generiranje desetsekundnega posnetka torej traja vsaj minuto ali dve, če ne bi bilo nobene čakalne vrste. To ni malo.
Te prve generativne mreže so iz slik delale druge slike, rezultati pa so bili tedaj osupljivi, z današnjega gledišča pa primitivni. Takšen GAN je uporabljala znamenita aplikacija FakeApp, ki je leta 2018 obnorela svet (Putin ali Pahor?, Monitor 03/18). Pomemben korak naprej se je zgodil leta 2021, ko je postala širšim množicam dostopna tehnologija pretvarjanje besedila v slike. Tistega leta je OpenAI izdal DALL-E 1, ki je bil simpatično nemočen. Rezultati so bile slike, ki jim je do kakršnekoli prepričljivosti manjkalo še ogromno, prekašali pa so jih nadarjeni osnovnošolci. A počasi se daleč pride, OpenAI pa sploh ni šel počasi.
Leta 2022 je izšel neprimerljivo boljši DALL-E 2, leta 2023 pa DALL-E 3, ki je danes integriran tudi v ChatGPT. GPT-4o riše še bolje. Na prelomu desetletja so se začeli pojavljati tudi modeli za pretvarjanje besedila v videoposnetke, ki so iz univerzitetnih laboratorijev hitro preskočili v komercialne. Meta je leta 2022 pokazala Make-A-Video, Google je naredil Imagen Video, a to še niso bili zelo dodelani modeli. Zares se je začelo leta 2023 z Emujem in leto pozneje Lumierom. ByteDance je julija lani na Kitajskem izdal Jimeng AI, ki so mu sledila tudi druga kitajska podjetja. Februarja 2024 je še OpenAI pokazal prototip Sore, ki je od decembra lani dostopna vsem.
Prva generacija modelov, ki je uporabljala generativna kontradiktorna omrežja (GAN), se je umaknila difuzijskim modelom. Sora sodi v tretjo generacijo, torej med difuzijske modele za video. Ti začnejo s »praznim platnom«, kamor inkrementalno dodajajo čedalje več podrobnosti do končnega izdelka. To prazno platno ni belo, temveč je šum (npr. Gaussov šum), ki se korakoma ureja in »razšumi« (denoising) do slike ali videa.
V vsakem koraku model vzame predhodno sliko (ki je na začetku zgolj šum) in besedilni opis ter izdela sliko, ki ima nekoliko več detajlov oziroma vsebine. V prvem koraku je to še vedno šum, kjer pa se morda razpoznajo obrisi končnega kadra. Postopek se nato ponavlja in ponavlja, zato tvorjenje končnega rezultata traja tako dolgo. Število korakov je vnaprej določeno, prav tako tudi ločljivost, saj mora biti vhodni šum istih dimenzij kot želeni izdelek.
Da Sora deluje, se je morala najprej naučiti na nepredstavljivih količinah videoposnetkov. Od kod izvirajo podatki za njeno urjenje, OpenAI ni nikoli javno govoril, za kar obstajajo zelo dobri pravni razlogi. Špekuliramo pa lahko – in pri tem še zdaleč ne bomo prvi ali edini –, da je videla veliko Youtuba, Facebooka, Instagrama in precej odigranih iger (Twitch). Iz OpenAI smo slišali le neobvezujoče izjave, če je neki posnetek javno dostopen, ga je Sora morda uporabila kot material za urjenje. Ob tem pa lahko dodamo, da javna dostopnost še ne pomeni, da je tudi pravno dopustno tak posnetek sneti in uporabiti v izvedenih delih. OpenAI to ve, zato molči.
Kakorkoli, vsi ti posnetki potrebujejo tudi opise, ki so na internetu precej nekakovostni. Pomislimo na opise videoposnetkov na Youtubu, ki so daleč od vsebinskega povzetka. OpenAI je zato uporabil svoj model, ki je videoposnetke prepoznal in pripravil opise zanje, nato pa so jih poslali še skozi ChatGPT, ki je imel nalogo te strojno generirane opise spremeniti v opise, kakršne bi napisal človek. Razlog je samoumeven: Soro bodo uporabljali ljudje, ki pišejo kakor – ljudje.
Ta postopek se imenuje recaptioning in je ključen za delovanje Sore, saj si je OpenAI tako sam zagotovil kakovostne vhodne podatke za njen trening. Brez tega koraka bi bila Sora sposobna izdelovati dobre videoposnetke, a ti ne bi ustrezali navodilom uporabnikov, v najslabšem primeru pa sploh ne bi imeli smisla. Podatki so vse.
Googlov odgovor
Google je aprila letos izdal Vertex AI Media Studio, ki na enem mestu združuje orodja za ustvarjanje boljših pozivov, pripravo slik in generiranje videoposnetkov. Platforma je zgrajena na Vertex AI, ki je del Google Clouda. Z orodjem Imagen 3 lahko ustvarimo sliko, ki jo potem spremenimo v videoposnetek z orodjem Veo 2. Dodamo lahko pripovedovalca (voiceover) z orodjem Chirp, medtem ko Lyria ustvari glasbeno podlago. Vertex AI Media Studio torej vsebuje vse sestavine za izdelavo profesionalnih videoposnetkov z minimalnim znanjem kar iz domačega naslanjača. V praksi pa vseeno potrebujemo nemalo vaje in poskušanja.
Slika veo2.png
Ko je OpenAI uril Soro, so bili vsi vhodni videoposnetki podvrženi enakemu režimu. Najprej je v prvi fazi Video AutoEncoder analiziral videoposnetek in ga pretvoril v manjrazsežen prostor, ki se imenuje latentni prostor. Videoposnetek je namreč niz slik, ki jih sestavljajo pike (pixels), kar pa za obdelavo ni najprimernejše. Tu posnema človeški način gledanja, ko tudi nismo pozorni na posamezne pike, temveč na celoto in vsebino. Videoposnetek v latentnem prostoru predstavlja koncepte in gibanja, ne posameznih podrobnosti, ter je precej lažji za obdelavo.
V drugem koraku urjenja vsebino v latentnem prostoru, ki jo razstavijo v enodimenzionalni niz (linearizirajo), skupaj z opisom pošljejo v difuzijski transformer. Na tak način se iz latentnega prostora odstrani šum in to se ponavlja več korakov. Vsebino iz latentnega prostora pa je mogoče nazaj dekodirati v gledljiv videoposnetek, kar opravi drugi model (decoder).
Delo v latentnem prostoru namesto v realnem ima nekaj ključnih prednosti. Tak način s trenutno računsko močjo ni le edini mogoč, temveč so tudi rezultati boljši. Model je namreč prisiljen razumeti, kaj se dogaja na videoposnetku, in ne zgolj slepo generirati slik, ki bi jih potem zlepil v video. S tem poveča realističnost, ohrani se konsistentnost med kadri (tako prostorska kot grafična), pristop pa je skalabilen.
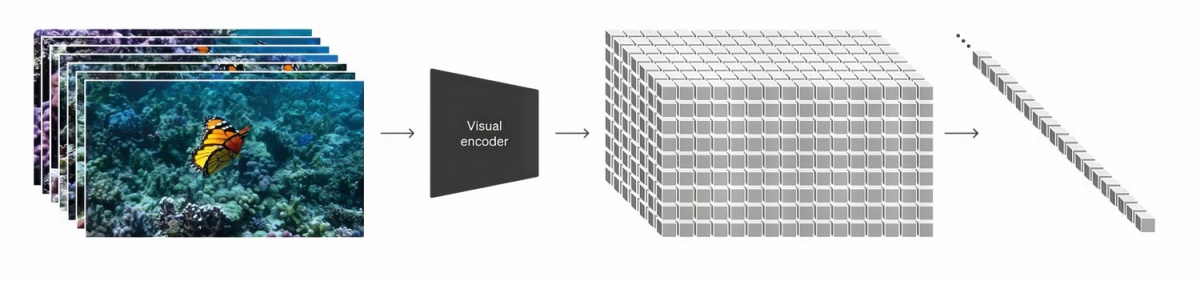
Pretvorba videoposnetka iz realnega prostora v latentnega.
Dejanski postopek je seveda precej bolj zapleten in se nekoliko razlikuje, če kot poziv uporabimo besedilo, sliko ali videoposnetek. Obsežen pregledni članek so objavili raziskovalci iz Microsoft Researcha in Univerze Lehigh, v katerem so analizirali delovanje tovrstnih modelov (Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models). OpenAI podrobnosti ne razkriva, a glavno inovacijo poznamo. Sora ustvarja koncepte, ne pikslov.
Dovolj dobro?
Sora je že povprečnim uporabnikom prinesla zmogljivosti, ki so bile pred petimi leti povsem nepredstavljive. Z malo znanja in časa je mogoče izdelati sorazmerno prepričljive videoposnetke ali slike, zato je kar nekoliko strašljivo pomisliti, kaj lahko storijo profesionalci, ki bi imeli na voljo neomejene količine časa, denarja in računske moči.
Različica, ki je trenutno na voljo sleherniku – in 20 dolarjev mesečno je dosegljivo sleherniku –, ima še nekaj pomanjkljivosti. Ostro oko bo na vsakem posnetku zlahka prepoznalo umetno inteligenco, in to ne samo zaradi vodnega žiga, ki ga s poceni paketa ni moč izbrisati. Pogosto se na posnetke prikradejo različni artefakti, ko kakšne podrobnosti s posnetka kar izginejo, ko se pojavijo nefizikalni prehodi, ko gibanje ni tekoče ali sploh smiselno.
Splošni vtisi so pozitivni, zapišemo pa lahko tudi nekaj kvalitativnih ugotovitev, ker bi za kvantitativni test morali opraviti precej več in bolje strukturiranih testov. A vendarle: Sora deluje dobro. Zanimivo je, da so krajši pozivi dali načelno boljše rezultate, nad 100 besedami pa se počasi izgubi fokus. Opis mora biti preprost, skorajda osnovnošolski. Kompleksnih tem ne zna dobro izrisati, abstraktna navodila so manj primerna. Sora razume navodilo, naj pes s slike pomaha z repom, ne pa tudi, naj nam zaželi dobro jutro. Sora v videoposnetke pretvarja scenarije, ne novel.
Nasploh je dobra pri lahkotnejših vsebinah, ki morajo imeti čim privlačnejšo grafiko. Če pa od nje zahtevamo zelo kompleksne posnetke, ki imajo več ravni abstrakcije, bo rezultat klavrn. Zelo priporočljivo je, da ji na kratko podamo opis kadra, nato pa še slog. Težave ima tudi s posnetki, ki so konceptualno nerealistični. Človek iz špagetov, ki kósi špagete, ni težava. Pristanek Nezemljanov v stari Ljubljani ali posnetek iz filma Rocky tudi ne. Ne bo pa znala narisati izjemno zapletenega opisa mesta. Seveda je bistveno uspešnejša, če ustvarja iz slike ali videoposnetka, ne le iz zapisa.
Ves čas pa moramo imeti v mislih, da je Sora pionir, ne pa zrela tehnologija. Če bo napredek res eksponenten ali pa vsaj paraboličen, bomo že čez nekaj let gledali neverjetno realistične videoposnetke. Photoshop je mrtev, kmalu bo tudi Premiere.
